
편집 요약 없음 |
|||
| (사용자 2명의 중간 판 44개는 보이지 않습니다) | |||
| 1번째 줄: | 1번째 줄: | ||
= 30일간의 SQL 기초 학습 = | |||
{{틀: | |||
| | == [[Special:WikiForum/SQL 30일 학습|SQL 30일 학습 묻고답하기(FAQ) ]] == | ||
<WikiForumThread id=1 replies=true /> | |||
{{틀:중요 | |||
|제목=오라클 설치는 [[oracle 19c Docker 설치|오라클 설치(도커 이용) ]] 를 참조 | |||
}} | }} | ||
== | ---- | ||
== 1일차 - SQL 기본 == | |||
{{:데이터 베이스 용어 설명}} | |||
---- | |||
== 2일차 - SELECT 구문 사용법 == | |||
{{:SELECT 구문}} | |||
---- | |||
== 3일차 - SELECT 구문 - WITH절 == | |||
{{:WITH 절}} | |||
---- | |||
== 4일차 - SELECT 구문 - GROUP BY절 == | |||
{{:GROUP BY 절}} | |||
---- | |||
== 5일차 - SELECT 구문 - JOIN == | |||
{{:SQL 조인}} | |||
---- | ---- | ||
== | |||
=== | == 6일차 - INSERT 구문 == | ||
{{:INSERT 구문}} | |||
== | |||
=== | ---- | ||
=== | |||
=== | == 7일차 - UPDATE 구문 == | ||
== | {{:UPDATE 구문}} | ||
---- | |||
== 8일차 - UPDATE 구문 == | |||
{{:MERGE 구문}} | |||
---- | |||
== 9일차 - SQL 활용 == | |||
{{:오라클SQL 과 안시SQL}} | |||
---- | |||
== 10일차 - SQL 활용 == | |||
{{:SQL 실행원리 와 과정}} | |||
== 11일차 - 최적의 SQL 작성법 == | |||
{{:최적의 SQL 작성법}} | |||
== 12일차 - 서브쿼리 == | |||
{{:스칼라 인라인뷰}} | |||
== 13일차 - 원도우 함수 == | |||
{{:원도우 함수}} | |||
== 14일차 - 그룹 함수 == | |||
{{:그룹 함수}} | |||
== 15일차 - 인덱스 == | |||
{{:인덱스}} | |||
== 16일차 - CONNECT BY 절 == | |||
{{:CONNECT BY 절}} | |||
== 17일차 - LATERAL == | |||
{{:LATERAL}} | |||
---- | |||
== 18일차 - 정규표현식(regular expression) == | |||
{{:정규표현식(regular expression)}} | |||
---- | |||
== 19일차 - PL/SQL 기초 == | |||
== 20일차 - PL/SQL 함수] == | |||
{{:함수}} | |||
== 21일차 - PL/SQL 프로시져] == | |||
{{:프로시져}} | |||
== 22일차 - PL/SQL 패키지 == | |||
{{:패키지}} | |||
== 23일차 - PL/SQL 트리거] == | |||
{{:트리거}} | |||
---- | ---- | ||
== | == 24일차 - SQL 고급 == | ||
2025년 7월 28일 (월) 00:56 기준 최신판
30일간의 SQL 기초 학습
SQL 30일 학습 묻고답하기(FAQ)
| 개요 > SQL 30일 학습 > SQL 30일 학습 묻고 답하기 > SQL 30일 학습 묻고 답하기 게시판입니다. |
| ||||
attach_file오라클 설치는 오라클 설치(도커 이용) 를 참조
1일차 - SQL 기본
데이터 베이스 기본 용어
- 데이터베이스 (Database, DB)
- 데이터를 체계적으로 저장하고 관리하는 시스템
- 단순히 정보를 모아놓는 것 이상으로, 효율적인 검색, 수정, 삭제 등이 가능
- 데이터 (Data)
- 현실 세계의 사실이나 값을 기록한 것
- 예를 들어, 고객의 이름, 주문 번호, 제품 가격 등이 데이터가 될 수 있음.
- 스키마 (Schema)
- 데이터베이스의 전체적인 구조와 제약 조건을 정의한 것을 말함
- 예를 들어, 건물을 짓기 전 설계도면과 같다고 생각하면 됨
- SQL (질의어)
- Structured Query Language,SQL은 데이터베이스에서 데이터를 관리하거나 조작하기 위해 설계된 표준 프로그래밍 언어
- QUERY(쿼리 - Query,SQL,질의어는 같은 의미를 가진다.)
- SQL 문장에서 데이터를 조회하는 명령어를 Query 라 함.
- 데이터를 검색(SELECT), 삽입(INSERT), 수정(UPDATE), 삭제(DELETE)하는 등의 작업을 할 때 사용
질의 > 학생들(STUDENTS) 에서 나이가 18보다 큰 학생의 이름과 ,나이를 조회 SQL > SELECT name, age FROM STUDENTS WHERE age > 18;
- TABLE (테이블)
- 데이터를 정리하고 표시하기 위한 행(row)과 열(column)로 구성된 구조, 표 처럼 행과 열로 구성되어 있음
- 엑셀 스프레드시트와 비슷하다고 생각하면 돰
=================== | Name | Age | City | =================== | Alice | 24 | New York | --------------------------------- | Bob | 30 | Chicago | ---------------------------------
- 테이블 생성 예시
CREATE TABLE students ( id INT PRIMARY KEY, name VARCHAR(100), age INT, city VARCHAR(100) );
- COLUMN (컬럼(열))
- 컬럼은 세로 줄, 열을 의미, 엑셀에서 세로줄과 유사
- Column/Field/Attribute 이라고 함
- 테이블에서 특정 종류의 데이터를 담고 있는 세로줄
- 예를 들어, '고객 이름', '주소', '전화번호' 등이 열이 됨
- 데이터값을 조회 하기위한 타이틀
=================== | Name | Age | City | ===================
- ROW (로우(행))
- 로우는 줄,행을 의미, 엑셀에서 가로줄과 유사 , 주로 1개의 줄을 레코드라고 한다.
- Row/Record/Tuple 라고 한다.
- 데이터의 값이 저장되어 있다.
| Alice | 24 | New York | --------------------------------- | Bob | 30 | Chicago |
- INDEX (인덱스)
- 데이터를 빠르게 검색하기 위해 사용하는 특별한 데이터 구조, 책에 있는 목차(INDEX) 와 유사
- VIEW (뷰)
- 데이터베이스에서는 가상 테이블을 의미, 테이블에 있는 일부 속성(컬럼)을 사용하고 할때 사용
- 기본 키 (Primary Key, PK): 테이블에서 각 행을 고유하게 식별할 수 있는 하나 이상의 열(또는 열들의 집합)이에요. 주민등록번호처럼 각 행을 유일하게 구분하는 역할을 해요.
- 외래 키 (Foreign Key, FK): 다른 테이블의 기본 키를 참조하는 열이에요. 여러 테이블 간의 관계를 설정하는 데 사용돼요. 예를 들어, 주문 테이블에 고객 테이블의 고객 ID가 외래 키로 있을 수 있어요.
- SELECT: 데이터베이스에서 데이터를 조회할 때 사용하는 SQL 명령문이에요.
- INSERT: 데이터베이스에 새로운 데이터를 추가할 때 사용하는 SQL 명령문이에요.
- UPDATE: 데이터베이스에 저장된 기존 데이터를 수정할 때 사용하는 SQL 명령문이에요.
- DELETE: 데이터베이스에 저장된 데이터를 삭제할 때 사용하는 SQL 명령문이에요.
- 트랜잭션 (Transaction): 데이터베이스의 상태를 변경시키는 논리적인 작업 단위예요. 모든 작업이 성공적으로 완료되거나, 아니면 모든 작업이 취소되어 원래 상태로 돌아가는 '원자성'을 가져요. (예: 은행 계좌 이체)
- 커밋 (Commit): 트랜잭션의 모든 변경 사항을 데이터베이스에 영구적으로 반영하는 명령이에요.
- 롤백 (Rollback): 트랜잭션 도중 오류가 발생하거나 취소하고 싶을 때, 변경 사항을 모두 취소하고 이전 상태로 되돌리는 명령이에요.
- 인덱스 (Index): 데이터베이스 테이블에서 원하는 데이터를 빠르게 찾을 수 있도록 돕는 구조예요. 책의 찾아보기와 비슷하다고 생각하시면 돼요. 인덱스가 없으면 데이터를 찾기 위해 모든 데이터를 스캔해야 할 수 있어요.
- 백업 (Backup): 데이터 손실에 대비하여 데이터베이스의 데이터를 복사해 두는 작업이에요.
- 복구 (Recovery): 손상된 데이터베이스를 백업된 데이터를 이용하여 이전 상태로 되돌리는 작업이에요.
데이터베이스 시스템 관련 용어
- DBMS (Database Management System): 데이터베이스를 관리하고 운영하는 소프트웨어 시스템이에요. Oracle, MySQL, SQL Server, PostgreSQL 등이 대표적인 DBMS예요.
- 서버 (Server): 데이터베이스를 저장하고 쿼리 요청을 처리하는 컴퓨터 또는 프로그램이에요.
- 클라이언트 (Client): 서버에 접속하여 데이터베이스를 이용하는 사용자 프로그램이나 응용 프로그램이에요.
이 외에도 업무에 따라 더 전문적인 용어들이 있겠지만, 위에 설명해 드린 용어들은 데이터베이스를 이용한 업무를 할 때 가장 기본적이고 핵심적인 개념들이니 알아두시면 많은 도움이 될 거예요.
현업에서 사용하는 업무 용어
모델링
- 데이터베이스에서 사용하는 테이블과 컬럼을 설계 하는 업무
- 주로 논리 모델은 모델링 단계를 의미하고 물리모델은 데이터베이스에 적용하는 단계를 의미함
Entity(엔터티)
- 주로 논리모델링에서 사용하는 용어로 속성을 포함하고 있는 객체를 의미함.
- 물리모델에서는 엔터티를 테이블이라 함.
ERD
- Entity Relationship Diagram
엔터티의 관계를 다이어그램으로 나타낸 도표
DW(데이터웨어하우스)
- 현업 업무는 실시간 업무를 처리 하는 기간계와 통계성 업무를 처리하는 정보계로 나누어짐
- OLTP 업무는 기간계 , OLAP 업무는 정보계라 칭함
ASIS 시스템
- 현재 개발중인 시스템(TOBE)에서 과거(이전)나 현재 운영중인 시스템을 부를때 칭함.
- 주로 레거시 나 AS-IS 라 칭함
TOBE 시스템
- 현재 개발중인 시스템을 칭함
- 주로 차세대라 칭함.
SQL 종류
- DDL DML DCL TCL
DDL (Data Definition Language; 데이터 정의 언어)
- 데이터 정의어
- :데이터베이스의 구조를 만들고 변경,수정 하는 명령어
- - CREATE TABLE : 테이블 생성
- - ALTER TABLE : 테이블 수정
- - DROP TABLE : 테이블 삭제
- - CREATE INDEX : 인덱스 생성
- - ALTER INDEX : 인덱스 수정
- - DROP INDEX : 인덱스 삭제
DML (Data Manipulation Language; 데이터 조작 언어)
- 데이터 조작어
- :테이블 안의 데이터를 넣고, 바꾸고, 지우고, 조회하는 데 사용해요.
- - SELECT
- - SELECT INTO
- - INSERT
- - DELETE
- - UPDATE
- - CREATE SEQUENCE
- - ALTER SEQUENCE
- - DROP SEQUENCE
DCL (Data Control Language : 데이터 제어 언어)
- 데이터 제어어
- 사용자 권한을 관리해요. 누가 무엇을 할 수 있는지 정해요.
- - CREATE USER
- - ALTER USER
- - GRANT
- TCL (Transaction Control Language; 트랜잭션 제어 언어)
- - COMMIT
- - ROLLBACK
DDL (Data Definition Language; 데이터 정의 언어)
- CREATE / ALTER / DROP [테이블 or 인덱스]
CREATE TABLE (테이블 생성)
CREATE TABLE 테이블명 ( 컬럼명 컬럼 타입 , ... , <column-name-n> <type> ) [tablespace 테이블스페이스명] -- 생략시 default tablespace에 생성. ;
ALTER TABLE (테이블 변경)
- 컬럼 추가
ALTER TABLE 테이블명 ADD ( 컬럼명 데이터타입, ...<column-name-n> <type> );
- 컬럼 수정
ALTER TABLE 테이블명 MODIFY ( 컬럼명 새로운타입 );
- 컬럼 삭제
ALTER TABLE 테이블명 DROP COLUMN 컬럼명;
DROP TABLE (테이블 삭제)
DROP TABLE 테이블명 ;
CREATE INDEX (인덱스 생성)
CREATE INDEX 인덱스명 ON 테이블명 ( 컬럼1,컬럼2, ... );
ALTER INDEX (인덱스 수정)
- 인덱스 재생성 (통계정보 수집은 동시에 )
-- COLLECTING STATISTICS ON INDEX ALTER INDEX 인덱스 REBUILD COMPUTE STATISTICS; -- 인덱스를 통계정보화 함께 리빌드 한다.
- 인덱스명 변경
-- RENAME INDEX ALTER INDEX 인덱스명 RENAME TO 새 인덱스명;
DROP INDEX (인덱스 삭제)
DROP INDEX 인덱스명;
DML (Data Manipulation Language; 데이터 조작 언어)
SELECT (조회)
SELECT 컬럼명1, 컬럼명2, ..., <column-name-n> FROM 테이블명1,테이블명2, ..., <table-name-n> WHERE <조건 표현 구문 > GROUP BY <그룹핑 컬럼>, ..., <grouping-column-name-n> HAVING <그룹핑 표현구문> ORDER BY <정렬 컬럼1>, ..., <order-column-name-n> ;
INSERT (입력)
- 전체 데이터 입력시
-- INSERT ALL VALUES INSERT INTO 테이블명 VALUES ( 값1, ..., <value-n> );
- 부분 데이터 입력시
-- INSERT SOME VALUES INSERT INTO 테이블명 ( 컬럼명1, ..., <column-name-n> ) VALUES ( 값1, ..., <value-n> );
DELETE (삭제)
DELETE FROM 테이블명 WHERE 조건표현구문;
UPDATE (갱신)
UPDATE 테이블명 SET 컬럼명 = <value> WHERE 조건표현구문
CREATE SEQUENCE (순서/번호 채번)
CREATE SEQUENCE 시퀀스명 MINVALUE <min-value> MAXVALUE <max-value> START WITH <start-value> INCREMENT BY <step-value> CACHE <cache-value>
ALTER SEQUENCE (순번 변경)
-- ALTER MINVALUE 최소값 변경 ALTER SEQUENCE 시퀀스명 MINVALUE <new-min-value>; -- ALTER MAXVALUE 최대값 변경 ALTER SEQUENCE 시퀀스명 MAXVALUE <new-max-value>; -- ALTER INCREMENT 증가값 변경 ALTER SEQUENCE 시퀀스명 INCREMENT BY <new-step-value>; -- SET CYCLE OR NOCYCLE 순환 여부 변경 ALTER SEQUENCE 시퀀스명 <CYCLE | NOCYCLE>; -- ALTER CACHE 캐시 건수 변경 ALTER SEQUENCE 시퀀스명 CACHE <new-cache-value>;
DROP SEQUENCE
DROP SEQUENCE 시퀀스명;
DCL (Data Control Language; 데이터 제어 언어)
- CREATE USER
CREATE USER 유저명 IDENTIFIED BY <user-password>;
- ALTER USER
ALTER USER 유저명 IDENTIFIED BY <new-user-password>;
- GRANT
GRANT 권한 TO 유저명;
TCL (Transaction Control Language; 트랜잭션 제어 언어)
- COMMIT
- ROLLBACK
2일차 - SELECT 구문 사용법
SELECT 기본 구문
| 명령어 | 설명 |
|---|---|
| SELECT | 테이블에 있는 속성을 지정하여 데이터를 조회하는 명령어 (주로 속성(컬럼)을 기술) |
| FROM | 데이터가 있는 테이블이나 뷰를 지정하는 명령어 (주로 테이블, 뷰, 인라인뷰 등을 기술) |
| WHERE | 데이터를 조회하는 조건을 지정하는 명령어 (주로 조건을 기술) |
| GROUP BY | 특정 속성을 기준으로 그룹화하여 검색할 때 사용하는 명령어 (주로 SELECT 절에 사용된 속성을 그룹핑할 때 기술) |
| HAVING | 그룹화된 속성에 조건을 지정하는 명령어 (주로 ~보다 크거나 작은 경우, 같은 경우를 지정) |
| ORDER BY | 정렬 명령어 (주로 속성값에 오름차순, 내림차순 속성을 지정) |
SELECT 기본 예제
예제 1. 부서/사원 조회
- 부서별 평균 급여가 5000 이상인 부서 중
- 2005년 이후 입사한 사원만 조회하여
- 평균 급여가 높은 순으로 정렬
SELECT department_id AS 부서번호 , COUNT(*) AS 사원수 , ROUND(AVG(salary), 0) AS 평균급여 , MAX(hire_date) AS 최근입사일 FROM employees -- 2005년 이후 입사한 사원만 조회 WHERE hire_date > TO_DATE('2005-01-01', 'YYYY-MM-DD') -- 부서별 평균 급여가 5000 이상인 부서 GROUP BY department_id HAVING AVG(salary) >= 5000 -- 평균 급여가 높은 순으로 정렬 ORDER BY 평균급여 DESC;
예제 2. 제품 판매 분석
- 2023년 분기별, 카테고리별 판매액 집계
- 총 판매액이 100만원 이상인 그룹만 표시
- 분기와 카테고리 순으로 정렬
SELECT TO_CHAR(sale_date, 'Q') AS 분기 , product_category AS 카테고리 , COUNT(*) AS 판매건수 , SUM(sale_amount) AS 총판매액 , AVG(sale_amount) AS 평균판매액 FROM sales -- 2023년 분기별, WHERE sale_date BETWEEN TO_DATE('2023-01-01', 'YYYY-MM-DD') AND TO_DATE('2023-12-31', 'YYYY-MM-DD') -- 판매액 별,카테고리별 그룹 GROUP BY TO_CHAR(sale_date, 'Q'), product_category -- 총 판매액이 100만원 이상 HAVING SUM(sale_amount) >= 1000000 ORDER BY 분기 ASC, 총판매액 DESC;
예제 3. 학생 성적 조회
- 각 학과별로 성적이 80점 이상인 학생들만 집계
- 학과 평균이 85점 이상인 그룹만 선택
- 평균 점수 순으로 정렬
SELECT department AS 학과 , COUNT(*) AS 학생수 , ROUND(AVG(score), 1) AS 평균점수 , MAX(score) AS 최고점수 , MIN(score) AS 최저점수 FROM students -- 성적이 80점 이상인 WHERE score >= 80 -- 학과 평균이 85점 이상인 그룹만 GROUP BY department HAVING AVG(score) >= 85 -- 평균 점수 순으로 정렬 ORDER BY 평균점수 DESC;
예제 4. 고객 구매 패턴 조회(ANSI SQL)
- 연간 구매액 500만원 이상
- 2022년에 구매한 고객별 구매 통계
- 총 구매액 순으로 정렬
SELECT c.customer_id AS 고객ID , c.customer_name AS 고객명 , COUNT(o.order_id) AS 주문횟수 , SUM(o.order_amount) AS 총구매액 , MAX(o.order_date) AS 최근구매일 FROM customers c JOIN orders o ON c.customer_id = o.customer_id -- 2022년에 연간 WHERE o.order_date BETWEEN TO_DATE('2022-01-01', 'YYYY-MM-DD') AND TO_DATE('2022-12-31', 'YYYY-MM-DD') -- 구매액이 500만원이상 구매한 고객아이디,고객명 그룹별 GROUP BY c.customer_id, c.customer_name HAVING SUM(o.order_amount) >= 5000000 -- 총 구매액 순으로 정렬 ORDER BY 총구매액 DESC;
3일차 - SELECT 구문 - WITH절
WITH 절 (CTE)
- (영문)The WITH clause lets you define a temporary result set (also called a CTE: Common Table Expression) that you can refer to within your main query.
- (한글)WITH 절은 *임시 테이블(=서브쿼리 결과)을 먼저 정의하고, 그걸 메인 쿼리에서 재사용할 수 있게 해주는 문법이에요.또한, CTE 라고 불려요
왜 사용할까?
- 복잡한 서브쿼리를 미리 이름 붙여서 정리할 수 있음
- 가독성 좋아짐
- 쿼리 재사용 가능 (같은 서브쿼리를 여러 번 쓰지 않아도 됨)
- 중첩된 서브쿼리를 피할 수 있음
기본 문법
WITH 임시이름 AS (
서브쿼리
)
SELECT ...
FROM 임시이름;
사용 예제
예제 테이블: sales
| id | product | amount | year |
|---|---|---|---|
| 1 | Laptop | 2000 | 2023 |
| 2 | Phone | 1500 | 2023 |
| 3 | Laptop | 2200 | 2024 |
| 4 | Phone | 1800 | 2024 |
| 5 | Laptop | 2500 | 2024 |
⸻
예제 1: 2024년 판매 데이터만 따로 떼어서 분석
WITH sales_2024 AS (
SELECT *
FROM sales
WHERE year = 2024
)
SELECT product, SUM(amount) AS total
FROM sales_2024
GROUP BY product;
결과
| product | total |
|---|---|
| Laptop | 4700 |
| Phone | 1800 |
설명: WITH sales_2024라는 임시 테이블을 만들어 2024년 데이터만 분리하고, 그걸 기준으로 제품별 총 판매액을 계산했어요.
⸻
예제 2: WITH 절을 두 개 이상 사용하는 경우
WITH
sales_2023 AS (
SELECT * FROM sales WHERE year = 2023
),
sales_2024 AS (
SELECT * FROM sales WHERE year = 2024
)
SELECT '2023' AS year, product, SUM(amount) AS total
FROM sales_2023
GROUP BY product
UNION ALL
SELECT '2024' AS year, product, SUM(amount) AS total
FROM sales_2024
GROUP BY product;
결과
| year | product | total |
|---|---|---|
| 2023 | Laptop | 2000 |
| 2023 | Phone | 1500 |
| 2024 | Laptop | 4700 |
| 2024 | Phone | 1800 |
설명: 연도별로 따로 나눈 데이터를 UNION ALL로 합쳐서 보여줍니다.
⸻
WITH 절 vs 서브쿼리
| 항목 | WITH 절 | 서브쿼리 |
|---|---|---|
| 가독성 | 매우 높음 | 복잡하면 읽기 어려움 |
| 재사용 | 가능 (한 번 정의해서 여러 번 사용) | 동일 쿼리를 반복 작성해야 함 |
| 성능 | Oracle이 내부적으로 최적화 가능 | 중복 계산 발생 시 성능 저하 가능 |
주의사항
- Oracle 11g 이상부터 지원되며, Oracle 19c에서도 완벽히 사용 가능
- WITH 절은 SELECT, INSERT, UPDATE, DELETE에도 사용할 수 있음
- WITH 절 내 쿼리에는 ORDER BY를 직접 넣을 수 없음 (단, ROW_NUMBER()와 함께 정렬 가능)
⸻
요약 정리
| 개념 | 설명 |
|---|---|
| WITH 절 | 서브쿼리를 임시 테이블처럼 이름 붙여 사용 |
| 장점 | 쿼리 재사용, 가독성 향상, 유지보수 용이 |
| 사용 예 | 복잡한 쿼리 정리, 여러 조건 조합 분석 등 |
WITH 절 고급
- 재귀 CTE(Common Table Expression)는 WITH 절 안에서 자기 자신을 호출해서 계층적으로 데이터를 조회할 수 있는 기능입니다.
- 주로 트리 구조, 부서-직원, 폴더-파일, 부모-자식 관계 등 계층형 데이터를 처리할 때 사용합니다.
기본 구조
WITH cte_name (컬럼들) AS (
-- anchor (기준이 되는 첫 번째 쿼리)
SELECT ...
FROM ...
WHERE ...
UNION ALL
-- recursive (재귀적으로 자기 자신 호출)
SELECT ...
FROM 원본테이블 t
JOIN cte_name c ON t.parent_id = c.id
)
SELECT * FROM cte_name;
⸻
실전 예제: 조직도 계층 구조 조회
예제 테이블: employees
| emp_id | name | manager_id |
|---|---|---|
| 1 | CEO | NULL
|
| 2 | Alice | 1 |
| 3 | Bob | 1 |
| 4 | Carol | 2 |
| 5 | David | 2 |
| 6 | Eve | 3 |
⸻
목표
CEO → 부하 직원 → 그 밑 직원 순으로 전체 조직 계층도를 출력하고 싶어요.
⸻
쿼리
WITH org_chart (emp_id, name, manager_id, level) AS (
-- Anchor: 최상위 관리자 (CEO)
SELECT emp_id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- Recursive: 상위 직원의 부하직원들
SELECT e.emp_id, e.name, e.manager_id, oc.level + 1
FROM employees e
JOIN org_chart oc ON e.manager_id = oc.emp_id
)
SELECT LPAD(' ', (level - 1) * 4) || name AS indented_name, level
FROM org_chart
ORDER BY level, emp_id;
⸻
결과
| indented_name | level |
|---|---|
| CEO | 1 |
| Alice | 2 |
| Bob | 2 |
| Carol | 3 |
| David | 3 |
| Eve | 3 |
설명: LPAD를 이용해서 직원 이름 앞에 공백을 넣어 들여쓰기 효과를 주었고, level을 이용해 계층을 구분했어요.
⸻
실전 활용:
메뉴 구조, 카테고리 분류, 댓글 트리 등
- 게시판 댓글 (대댓글)
- 온라인 쇼핑몰 카테고리 (대분류 > 중분류 > 소분류)
- 파일 시스템 (폴더 > 하위 폴더 > 파일)
- 사내 조직도
⸻
주의사항 (Oracle 19c 기준)
| 항목 | 설명 |
|---|---|
| RECURSIVE 키워드 | Oracle에서는 쓰지 않습니다. PostgreSQL 같은 DBMS에서만 필요합니다. |
| UNION ALL 필수 | 재귀 CTE는 반드시 UNION ALL로 이어야 합니다. |
| LEVEL, CONNECT BY | 기존의 Oracle 계층 쿼리 방식 (CONNECT BY)와도 유사한 역할을 합니다. |
⸻
CONNECT BY vs WITH 재귀
| 특징 | CONNECT BY | WITH 재귀(CTE) |
|---|---|---|
| 문법 | Oracle 전용 문법 | 표준 SQL 방식 (Oracle에서도 지원됨) |
| 읽기 쉬움 | 간단하지만 복잡해지면 어려움 | 가독성 높음, 유연함 |
| 순서 제어 | ORDER SIBLINGS BY 필요 | 그냥 ORDER BY 사용 가능 |
| 컬럼 추가 유연성 | 낮음 | WITH에 원하는 컬럼 자유롭게 추가 가능 |
⸻
실전 시나리오별 WITH 절 (특히 재귀 CTE 포함)을 예제
시나리오 1: 조직도 조회 (부서장 → 직원 트리 구조)
상황
- 인사팀에서 조직도를 트리 형태로 보고 싶어합니다.
- employees 테이블에는 emp_id, name, manager_id가 있고, 누가 누구의 상사인지 정보가 들어 있습니다.
쿼리 예제
WITH org AS (
SELECT emp_id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.emp_id, e.name, e.manager_id, o.level + 1
FROM employees e
JOIN org o ON e.manager_id = o.emp_id
)
SELECT LPAD(' ', (level - 1) * 4) || name AS name, level
FROM org
ORDER BY level, emp_id;
활용 목적: 사내 인트라넷 조직도, 상하 관계 파악, 평가 구조 설계
시나리오 2: 게시판 댓글 트리 조회
상황
- 게시판에서 댓글-대댓글 구조를 조회해야 합니다.
- comments 테이블: comment_id, parent_id, content
쿼리 예제
WITH reply_tree AS (
SELECT comment_id, parent_id, content, 1 AS depth
FROM comments
WHERE parent_id IS NULL
UNION ALL
SELECT c.comment_id, c.parent_id, c.content, r.depth + 1
FROM comments c
JOIN reply_tree r ON c.parent_id = r.comment_id
)
SELECT LPAD(' ', (depth - 1) * 4) || content AS content_tree
FROM reply_tree;
활용 목적: 커뮤니티 사이트, 포럼, 블로그 댓글 관리
시나리오 3: 제품 카테고리 분류 트리
상황
- 온라인 쇼핑몰에서 상품이 속한 카테고리를 트리로 관리하고 싶어요.
- categories 테이블: category_id, parent_id, name
쿼리 예제
WITH category_tree AS (
SELECT category_id, parent_id, name, 1 AS level
FROM categories
WHERE parent_id IS NULL
UNION ALL
SELECT c.category_id, c.parent_id, c.name, ct.level + 1
FROM categories c
JOIN category_tree ct ON c.parent_id = ct.category_id
)
SELECT LPAD(' ', (level - 1) * 2) || name AS category_path
FROM category_tree
ORDER BY level, name;
활용 목적: 카테고리 트리 메뉴 생성, 상품 등록 시 분류 관리
시나리오 4: 연속 날짜 생성 (캘린더 만들기)
상황
- 날짜 기준 보고서 작성 시 날짜 테이블이 없으면 어려움.
- WITH 절로 임시 날짜 테이블을 생성해서 활용 가능.
쿼리 예제: 2024년 1월 1일~10일까지 날짜 생성
WITH dates (dt) AS (
SELECT TO_DATE('2024-01-01', 'YYYY-MM-DD') FROM dual
UNION ALL
SELECT dt + 1 FROM dates
WHERE dt + 1 <= TO_DATE('2024-01-10', 'YYYY-MM-DD')
)
SELECT dt FROM dates;
활용 목적: 일별 매출 집계, 출근/결근 현황 분석, 캘린더 생성
시나리오 5: 누적 매출 구하기 (누적합)
상황
- 시간 순으로 누적 매출을 보여줘야 하는 보고서.
- sales 테이블: sale_date, amount
WITH daily_sales AS (
SELECT sale_date, amount
FROM sales
WHERE sale_date BETWEEN DATE '2024-01-01' AND DATE '2024-01-10'
),
running_total AS (
SELECT ds1.sale_date, ds1.amount,
(SELECT SUM(ds2.amount)
FROM daily_sales ds2
WHERE ds2.sale_date <= ds1.sale_date) AS cumulative_total
FROM daily_sales ds1
)
SELECT * FROM running_total
ORDER BY sale_date;
활용 목적: 기간 누적 매출, 사용자 활동 누적, 진도율 계산 등
실전 활용 요약
| 시나리오 | 핵심 목적 | 활용 분야 |
|---|---|---|
| 조직도 | 계층 구조 조회 | 인사 시스템 |
| 댓글 | 댓글-대댓글 구조 트리화 | 커뮤니티, 블로그 |
| 카테고리 분류 | 대/중/소 분류 트리화 | 쇼핑몰, 콘텐츠 플랫폼 |
| 날짜 생성 | 연속 날짜 생성 | 보고서, 캘린더, 출석부 |
| 누적 매출 | 시간 순 누적 값 계산 | 통계 보고서, 재무 데이터 |
4일차 - SELECT 구문 - GROUP BY절
GROUP BY 절
- (영문): GROUP BY is used to group rows that have the same values in specified columns into summary rows.
- (한글): GROUP BY는 특정 컬럼 값을 기준으로 같은 값들끼리 묶어서 결과를 보여주는 SQL 절입니다.
특징
집계 함수(예: COUNT(), SUM(), AVG(), MAX(), MIN())와 함께 자주 사용됩니다.
데이터를 그룹별 요약하거나 분류해서 볼 수 있습니다.
사용 방법
SELECT 컬럼명, 집계함수 FROM 테이블명 GROUP BY 컬럼명;
예제
employees 테이블 예시
| emp_id | name | department | salary |
|---|---|---|---|
| 1 | John | Sales | 3000 |
| 2 | Alice | Sales | 3200 |
| 3 | Bob | IT | 4000 |
| 4 | Carol | IT | 4200 |
| 5 | David | HR | 2800 |
예제 1: 부서별 평균 급여 구하기
SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department;
- 조회 결과
| department | avg_salary |
|---|---|
| Sales | 3100 |
| IT | 4100 |
| HR | 2800 |
설명: department(부서)별로 묶어서, 각 부서의 salary(급여) 평균을 구한 것입니다.
예제 2: 부서별 직원 수 구하기
SELECT department, COUNT(*) AS num_employees FROM employees GROUP BY department;
- 조회 결과
| department | num_employees |
|---|---|
| Sales | 2 |
| IT | 2 |
| HR | 1 |
설명: GROUP BY department를 통해 부서별로 직원 수를 센 것입니다.
주의사항
GROUP BY에 사용하지 않은 컬럼은 SELECT절에 직접 쓸 수 없습니다. (단, 집계 함수(max(),count(),sum()..) 안에 들어가는 경우는 예외)
GROUP BY는 정렬 기능이 아닙니다. 정렬은 ORDER BY를 사용해야 합니다.
GROUP BY 절 고급
HAVING 절
HAVING은 GROUP BY로 그룹화한 결과에 조건을 거는 절입니다.
WHERE는 그룹화 전에 조건, HAVING은 그룹화 후 조건입니다.
예제 테이블: sales
| id | product | region | amount |
|---|---|---|---|
| 1 | Laptop | Seoul | 2000 |
| 2 | Laptop | Busan | 1500 |
| 3 | Phone | Seoul | 1000 |
| 4 | Phone | Busan | 1200 |
| 5 | Laptop | Seoul | 2200 |
| 6 | Phone | Seoul | 1300 |
예제 1: 지역별로 제품 판매 총합이 3000 이상인 경우만 보기
SELECT region, SUM(amount) AS total_sales FROM sales GROUP BY region HAVING SUM(amount) >= 3000;
결과
| region | total_sales |
|---|---|
| Seoul | 5500 |
설명: GROUP BY region으로 지역별로 묶고, HAVING을 통해 총합이 3000 이상인 지역만 필터링합니다.
다중 컬럼 GROUP BY
개념 • 두 개 이상의 컬럼을 기준으로 복합적으로 그룹화할 수 있습니다.
예제 2: 지역 + 제품별 판매 총액 구하기
SELECT region, product, SUM(amount) AS total_sales FROM sales GROUP BY region, product;
결과
| 지역 | 제품 | 매출액(USD) |
|---|---|---|
| Seoul | Laptop | 4,200 |
| Seoul | Phone | 2,300 |
| Busan | Laptop | 1,500 |
| Busan | Phone | 1,200 |
설명: region과 product를 동시에 그룹화하여, 각 지역-제품 조합별로 총 판매량을 계산했습니다.
GROUP BY + JOIN 활용
복잡한 데이터 분석에는 JOIN과 GROUP BY를 함께 사용합니다.
예제 테이블
- employees
| 사원 ID | 이름 | 부서 ID |
|---|---|---|
| 1 | John | 10 |
| 2 | Alice | 10 |
| 3 | Bob | 20 |
- departments
| 부서 ID | 부서 이름 |
|---|---|
| 10 | Sales |
| 20 | IT |
- salaries
| 사원 ID | 급여 (USD) |
|---|---|
| 1 | 3,000 |
| 2 | 3,500 |
| 3 | 4,000 |
부서별 평균 급여 구하기 (JOIN 사용)
SELECT d.dept_name, AVG(s.salary) AS avg_salary FROM employees e JOIN departments d ON e.dept_id = d.dept_id JOIN salaries s ON e.emp_id = s.emp_id GROUP BY d.dept_name;
결과
| 부서명 | 평균 급여(USD) |
|---|---|
| Sales | 3,250 |
| IT | 4,000 |
| 전체 평균 | 3,625 |
설명: 여러 테이블을 JOIN해서 dept_name 기준으로 묶고 평균 급여를 계산했습니다.
ROLLUP (고급)
ROLLUP은 그룹별 합계 외에 **전체 합계(총계)**까지 같이 보여줍니다.
예제 4: 제품별 판매 총액과 전체 총액까지 보여주기
SELECT product, SUM(amount) AS total_sales FROM sales GROUP BY ROLLUP(product);
결과
| 제품 | 매출액(USD) |
|---|---|
| Laptop | 3,700 |
| Phone | 3,500 |
| 전체 합계 | 7,200 |
설명: NULL은 전체 총합을 의미합니다. 제품별 합계 + 전체 합계를 한 번에 볼 수 있습니다.
요점정리
| 개념 | 설명 | 사용 예시 |
|---|---|---|
| GROUP BY | 특정 컬럼 값으로 행을 그룹화 | SELECT dept, COUNT(*) FROM emp GROUP BY dept |
| HAVING | 그룹화된 결과에 필터링 조건 적용 (WHERE 절과 유사하지만 그룹 후 적용) |
SELECT dept, AVG(salary) FROM emp GROUP BY dept HAVING AVG(salary) > 5000 |
| 다중 그룹화 | 두 개 이상 컬럼으로 계층적 그룹화 | SELECT dept, gender, COUNT(*) FROM emp GROUP BY dept, gender |
| JOIN + GROUP BY | 여러 테이블 연결 후 그룹화 수행 | SELECT d.dept_name, COUNT(e.emp_id) FROM emp e JOIN dept d ON e.dept_id = d.dept_id GROUP BY d.dept_name |
| ROLLUP | 그룹별 소계 + 총계를 한 번에 출력 (다차원 분석용) |
SELECT dept, gender, SUM(salary) FROM emp GROUP BY ROLLUP(dept, gender) |
5일차 - SELECT 구문 - JOIN
Oracle 테이블 조인 (Table Join)
> 여러 테이블에서 관련된 데이터를 **하나의 결과로 결합**해서 보여주는 SQL 기능입니다.
예: 직원 정보는 `EMPLOYEES`, 부서 정보는 `DEPARTMENTS`에 있을 때
👉 직원 이름 + 부서 이름을 함께 보여주고 싶을 때 조인을 사용합니다.예제 테이블
-- EMPLOYEES 테이블 | EMP_ID | NAME | DEPT_ID | |--------|---------|---------| | 101 | Alice | 10 | | 102 | Bob | 20 | | 103 | Charlie | 10 | -- DEPARTMENTS 테이블 | DEPT_ID | DEPT_NAME | |---------|------------| | 10 | HR | | 20 | IT | | 30 | Marketing |
조인 종류
| 조인 종류 | 설명 |
|---|---|
| INNER JOIN | 두 테이블에서 일치하는 값이 있는 행만 보여줌 |
| LEFT OUTER JOIN | 왼쪽 테이블은 무조건 모두 출력, 오른쪽에 일치하는 값이 없으면 NULL |
| RIGHT OUTER JOIN | 오른쪽 테이블은 무조건 모두 출력, 왼쪽에 일치하는 값이 없으면 NULL |
| FULL OUTER JOIN | 양쪽 테이블을 모두 포함, 일치하지 않으면 NULL |
| CROSS JOIN (카테시안 조인) | 두 테이블의 모든 행 조합을 출력 (곱집합) |
| ANTI JOIN | 조건에 맞지 않는 행만 보여줌 (EXISTS가 아닌 NOT EXISTS 조건) |
INNER JOIN
SELECT E.EMP_ID, E.NAME, D.DEPT_NAME FROM EMPLOYEES E INNER JOIN DEPARTMENTS D ON E.DEPT_ID = D.DEPT_ID;
| EMP_ID | NAME | DEPT_NAME |
|---|---|---|
| 101 | Alice | HR |
| 102 | Bob | IT |
| 103 | Charlie | HR |
LEFT OUTER JOIN
SELECT E.EMP_ID, E.NAME, D.DEPT_NAME FROM EMPLOYEES E LEFT OUTER JOIN DEPARTMENTS D ON E.DEPT_ID = D.DEPT_ID;
- `EMPLOYEES`의 모든 직원은 다 나오고,
- 일치하지 않는 부서가 있으면 `DEPT_NAME`은 NULL
RIGHT OUTER JOIN
SELECT E.EMP_ID, E.NAME, D.DEPT_NAME FROM EMPLOYEES E RIGHT OUTER JOIN DEPARTMENTS D ON E.DEPT_ID = D.DEPT_ID;
- `DEPARTMENTS`의 모든 부서는 다 나오고,
- 직원이 없는 부서는 `EMP_ID`, `NAME`이 NULL
FULL OUTER JOIN
SELECT E.EMP_ID, E.NAME, D.DEPT_NAME FROM EMPLOYEES E FULL OUTER JOIN DEPARTMENTS D ON E.DEPT_ID = D.DEPT_ID;
- `EMPLOYEES`, `DEPARTMENTS` 둘 다 포함
- 한쪽에만 데이터가 있으면 다른 쪽은 NULL
CARTESIAN JOIN (CROSS JOIN)
SELECT E.EMP_ID, E.NAME, D.DEPT_NAME FROM EMPLOYEES E CROSS JOIN DEPARTMENTS D;
- 조인 조건 없이 **모든 행을 조합**
- EMPLOYEES가 3행, DEPARTMENTS가 3행이면 → 결과는 9행
| EMP_ID | NAME | DEPT_NAME |
|---|---|---|
| 101 | Alice | HR |
| 101 | Alice | IT |
| 101 | Alice | Marketing |
| 102 | Bob | HR |
| 102 | Bob | IT |
| ... | ... | ... |
> ❗ 주의: **WHERE 조건 없이 CROSS JOIN을 쓰면 큰 결과가 나올 수 있어 조심해야 합니다.** 카테시안 조인
ANTI JOIN (조건에 부합하지 않는 데이터만)
SELECT * FROM DEPARTMENTS D WHERE NOT EXISTS ( SELECT 1 FROM EMPLOYEES E WHERE E.DEPT_ID = D.DEPT_ID );
- **직원이 없는 부서만 조회**하는 예제입니다.
| DEPT_ID | DEPT_NAME |
|---|---|
| 30 | Marketing |
> ✅ 실무에서 **특정 값이 존재하지 않는 경우**를 찾을 때 많이 사용합니다.
요점정리
| 조인 종류 | 대표 SQL 구문 | 출력 대상 |
|---|---|---|
| INNER JOIN | A INNER JOIN B ON 조건 | A와 B 모두 조건에 맞는 데이터만 |
| LEFT OUTER JOIN | A LEFT OUTER JOIN B ON 조건 | A는 모두, B는 맞는 것만 |
| RIGHT OUTER JOIN | A RIGHT OUTER JOIN B ON 조건 | B는 모두, A는 맞는 것만 |
| FULL OUTER JOIN | A FULL OUTER JOIN B ON 조건 | A와 B 모두 포함 |
| CROSS JOIN | A CROSS JOIN B | 모든 조합 (곱집합) |
| ANTI JOIN | WHERE NOT EXISTS (서브쿼리) | 조건에 부합하지 않는 데이터 |
6일차 - INSERT 구문
INSERT 구문
- INSERT 구문은 테이블에 새로운 데이터를 추가할 때 사용됩니다.
기본 문법
INSERT INTO 테이블명 (컬럼1, 컬럼2, ...) VALUES (값1, 값2, ...);
- INSERT INTO: 데이터를 추가할 테이블명을 지정합니다.
- (컬럼1, 컬럼2, ...): 어떤 컬럼에 값을 넣을지를 지정합니다.
- VALUES (...): 해당 컬럼들에 대응하는 값을 입력합니다.
예제 1
1.간단한 데이터 추가
고객 정보를 담는 CUSTOMER 테이블이 아래와 같다고 가정하겠습니다.
ID (NUMBER) NAME (VARCHAR2) EMAIL (VARCHAR2)
SQL 예제:
INSERT INTO CUSTOMER (ID, NAME, EMAIL) VALUES (1, '홍길동', 'hong@example.com');
이 구문은 ID가 1이고 이름은 ‘홍길동’, 이메일은 ‘hong@example.com’인 고객 정보를 추가하는 것입니다.
⸻
예제 2
- 컬럼 이름 생략 (모든 컬럼에 값을 넣는 경우)
테이블의 컬럼 순서를 정확히 알고 계신 경우, 컬럼명을 생략하고 아래와 같이 작성하실 수도 있습니다.
INSERT INTO CUSTOMER VALUES (2, '김철수', 'kim@example.com');
※ 이 방법은 컬럼 순서가 바뀌지 않았을 때만 안전합니다. 컬럼 순서가 바뀌면 오류가 발생할 수 있습니다.
⸻
예제 3
- 다른 테이블에서 데이터 복사
다른 테이블의 데이터를 이용하여 INSERT하는 방법도 있습니다.
INSERT INTO CUSTOMER (ID, NAME, EMAIL) SELECT EMP_ID, EMP_NAME, EMP_EMAIL FROM EMPLOYEE WHERE DEPARTMENT = 'SALES';
위 구문은 EMPLOYEE 테이블에서 부서가 ‘SALES’인 직원을 CUSTOMER 테이블에 추가하는 예제입니다.
⸻
추가 팁
- 데이터를 추가한 후, COMMIT; 명령어를 실행하셔야 실제로 데이터가 저장됩니다.
- 만약 잘못 입력하셨다면, ROLLBACK;을 통해 마지막 COMMIT 이전 상태로 되돌릴 수 있습니다.
- 컬럼 수와 값의 수는 반드시 일치해야 합니다.
고급 기능
다음 기능들은 대량 데이터 처리, 조건부 삽입, 트랜잭션 제어 등에서 매우 유용합니다.
⸻
INSERT ALL — 여러 행을 한 번에 삽입 (다중 INSERT)
INSERT ALL INTO CUSTOMER (ID, NAME, EMAIL) VALUES (3, '이순신', 'lee@example.com') INTO CUSTOMER (ID, NAME, EMAIL) VALUES (4, '유관순', 'yoo@example.com') INTO CUSTOMER (ID, NAME, EMAIL) VALUES (5, '안중근', 'ahn@example.com') SELECT * FROM DUAL;
- INSERT ALL은 여러 레코드를 한 번에 삽입할 때 사용합니다.
- SELECT * FROM DUAL은 형식상 필요합니다. DUAL은 Oracle의 가상 테이블입니다.
INSERT FIRST — 조건에 맞는 첫 번째 문장만 실행
INSERT FIRST
WHEN SALARY > 5000 THEN
INTO HIGH_SAL_EMP (EMP_ID, NAME, SALARY) VALUES (EMP_ID, NAME, SALARY)
WHEN SALARY BETWEEN 3000 AND 5000 THEN
INTO MID_SAL_EMP (EMP_ID, NAME, SALARY) VALUES (EMP_ID, NAME, SALARY)
ELSE
INTO LOW_SAL_EMP (EMP_ID, NAME, SALARY) VALUES (EMP_ID, NAME, SALARY)
SELECT EMP_ID, NAME, SALARY
FROM EMPLOYEE;
- 이 구문은 조건에 따라 다른 테이블로 분기해서 삽입합니다.
- INSERT FIRST는 첫 번째 조건만 실행되며, 나머지는 건너뜁니다.
RETURNING INTO — INSERT한 후 값을 바로 변수에 저장 (PL/SQL에서 사용)
DECLARE
v_id NUMBER;
BEGIN
INSERT INTO CUSTOMER (ID, NAME, EMAIL)
VALUES (CUSTOMER_SEQ.NEXTVAL, '장보고', 'jang@example.com')
RETURNING ID INTO v_id;
DBMS_OUTPUT.PUT_LINE('삽입된 고객 ID: ' || v_id);
END;
- RETURNING INTO는 삽입 직후에 생성된 값을 변수에 즉시 저장합니다.
- 보통 시퀀스와 함께 자주 사용됩니다.
병렬 INSERT (대용량 INSERT 성능 향상)
ALTER SESSION ENABLE PARALLEL DML; INSERT /*+ PARALLEL(CUSTOMER, 4) */ INTO CUSTOMER (ID, NAME, EMAIL) SELECT EMP_ID, EMP_NAME, EMP_EMAIL FROM EMPLOYEE;
or
-- 12C 이상부터 힌트로 가능 INSERT /*+ ENABLE_PARALLEL_DML PARALLEL(CUSTOMER, 4) */ INTO CUSTOMER (ID, NAME, EMAIL) SELECT EMP_ID, EMP_NAME, EMP_EMAIL FROM EMPLOYEE;
- PARALLEL 힌트를 사용하면 여러 프로세스를 사용해 INSERT 속도 향상 가능
- 단, ENABLE PARALLEL DML 세션 설정이 필요합니다.
MERGE 문 (조건에 따라 INSERT 또는 UPDATE)
MERGE INTO CUSTOMER c USING TEMP_CUSTOMER t ON (c.ID = t.ID) WHEN MATCHED THEN UPDATE SET c.NAME = t.NAME, c.EMAIL = t.EMAIL WHEN NOT MATCHED THEN INSERT (ID, NAME, EMAIL) VALUES (t.ID, t.NAME, t.EMAIL);
- MERGE 문은 **“있으면 UPDATE, 없으면 INSERT”**의 로직을 한 번에 처리합니다.
- 대량의 동기화 작업에 매우 유용합니다.
7일차 - UPDATE 구문
기본 UPDATE 문법
UPDATE는 기존 데이터를 수정할 때 사용하는 명령어입니다.
▶ 기본 문법:
UPDATE 테이블명 SET 컬럼1 = 값1, 컬럼2 = 값2, ... WHERE 조건;
- SET: 변경하고 싶은 컬럼과 값을 지정합니다.
- WHERE: 어떤 행(row)을 수정할지 조건을 줍니다.
- WHERE 절이 없으면 테이블의 모든 행이 수정되므로 주의해야 합니다❗
▶ 예제 1: 고객 이메일 변경
UPDATE CUSTOMER SET EMAIL = 'new_email@example.com' WHERE ID = 1;
ID가 1번인 고객의 이메일을 변경합니다.
▶ 예제 2: 가격 일괄 인상
UPDATE PRODUCT SET PRICE = PRICE * 1.1;
전체 상품 가격을 10% 인상합니다 (WHERE 없이 전체 행 업데이트❗).
▶ COMMIT과 ROLLBACK
• COMMIT; 실행 시 변경 내용이 영구 저장됩니다. • ROLLBACK; 실행 시 마지막 COMMIT 이전 상태로 복구됩니다.
고급 UPDATE 기술
고급 기능은 실무에서 대량 처리, 조건 분기, 복잡한 참조 등에 매우 유용합니다.
▶ 예제 3: 서브쿼리를 이용한 UPDATE
UPDATE CUSTOMER c SET EMAIL = ( SELECT E.EMP_EMAIL FROM EMPLOYEE E WHERE E.EMP_ID = c.ID ) WHERE EXISTS ( SELECT 1 FROM EMPLOYEE E WHERE E.EMP_ID = c.ID );
EMPLOYEE 테이블에서 같은 ID를 가진 사람의 이메일로 CUSTOMER 테이블을 업데이트합니다.
▶ 예제 4: MERGE를 이용한 조건부 UPDATE or INSERT
MERGE INTO CUSTOMER c USING TEMP_CUSTOMER t ON (c.ID = t.ID) WHEN MATCHED THEN UPDATE SET c.NAME = t.NAME, c.EMAIL = t.EMAIL WHEN NOT MATCHED THEN INSERT (ID, NAME, EMAIL) VALUES (t.ID, t.NAME, t.EMAIL);
- MERGE는 업데이트 또는 없으면 삽입까지 자동 처리됩니다.
- 데이터 동기화에 자주 사용됩니다.
▶ 예제 5: RETURNING INTO — 변경된 값을 PL/SQL 변수에 받기
DECLARE
v_email VARCHAR2(100);
BEGIN
UPDATE CUSTOMER
SET EMAIL = 'update@example.com'
WHERE ID = 1
RETURNING EMAIL INTO v_email;
DBMS_OUTPUT.PUT_LINE('변경된 이메일: ' || v_email);
END;
- UPDATE한 결과를 변수에 즉시 받을 수 있어 후속 로직 처리에 유용합니다.
▶ 예제 6: 병렬 UPDATE (성능 최적화용)
ALTER SESSION ENABLE PARALLEL DML; UPDATE /*+ PARALLEL(CUSTOMER, 4) */ CUSTOMER SET STATUS = 'ACTIVE' WHERE JOIN_DATE < SYSDATE - 365;
병렬로 처리하여 대량 데이터 수정 속도 향상 단, PARALLEL DML 활성화가 필요합니다.
요점 정리
| 구분 | 기능 설명 | 예시 구문 유형 |
|---|---|---|
| 초급 | 기본적인 데이터 수정 | UPDATE ... SET ... WHERE |
| 고급 1 | 서브쿼리를 활용한 값 수정 | UPDATE ... SET = (SELECT) |
| 고급 2 | 조건부 INSERT/UPDATE 통합 처리 | MERGE INTO ... |
| 고급 3 | 변경 결과 즉시 변수에 받기 | RETURNING INTO |
| 고급 4 | 대용량 성능 최적화 (병렬 처리) | UPDATE /*+ PARALLEL */ |
8일차 - UPDATE 구문
MERGE 구문
- MERGE는 특히 ETL 작업, 데이터 동기화, UPSERT 작업에서 많이 사용돼요.
- (영문): The MERGE statement allows you to conditionally insert or update data in a target table based on the results of a join with a source table.
- (한글): MERGE는 하나의 SQL 문으로, 대상 테이블에 대해 조건에 따라 INSERT(삽입) 또는 **UPDATE(갱신)**를 할 수 있는 문법입니다. 흔히 “UPSERT” (update + insert)라고 부르기도 해요.
언제 쓰나요?
- A 테이블에 B 테이블 데이터를 넣고 싶은데, 이미 있는 데이터는 UPDATE 하고 없는 데이터는 INSERT 해야 할 때
- 데이터 동기화, 이력 테이블 관리, 배치 업데이트 등에서 자주 사용
기본 문법
MERGE INTO 대상테이블 t
USING 원본테이블 s
ON (t.기준컬럼 = s.기준컬럼)
WHEN MATCHED THEN
UPDATE SET t.컬럼1 = s.컬럼1, ...
WHEN NOT MATCHED THEN
INSERT (컬럼1, 컬럼2, ...)
VALUES (s.컬럼1, s.컬럼2, ...);
예제
예제 테이블
대상 테이블: target_employees
| ID | Employee | Monthly Salary |
|---|---|---|
| 1 | Alice | $3,000 |
| 2 | Bob | $3,200 |
원본 테이블: source_employees
| Employee ID | Name | Salary (USD) |
|---|---|---|
| 2 | Bob | 3,500 |
| 3 | Carol | 2,800 |
| emp_id | name | salary |
|---|---|---|
| 1 | Alice | 3000 |
| 2 | Bob | 3200 |
| emp_id | name | salary |
|---|---|---|
| 2 | Bob | 3500 |
| 3 | Carol | 2800 |
MERGE 쿼리
MERGE INTO target_employees t
USING source_employees s
ON (t.emp_id = s.emp_id)
WHEN MATCHED THEN
UPDATE SET t.salary = s.salary
WHEN NOT MATCHED THEN
INSERT (emp_id, name, salary)
VALUES (s.emp_id, s.name, s.salary);
실행 결과
| emp_id | name | salary |
|---|---|---|
| 1 | Alice | $3,000 |
| 2 | Bob | $3,500 |
| 3 | Carol | $2,800 |
조건 추가 (WHERE 사용)
WHEN MATCHED THEN
UPDATE SET t.salary = s.salary
WHERE s.salary > t.salary -- 조건 만족할 때만 갱신
WHEN NOT MATCHED THEN
INSERT (emp_id, name, salary)
VALUES (s.emp_id, s.name, s.salary)
WHERE s.salary >= 2500; -- 조건 만족할 때만 삽입
장점 요약
| 장점 | 설명 |
|---|---|
| 한 문장으로 처리 | MERGE INTO target t<br> USING source s<br> ON (t.id = s.id)<br> WHEN MATCHED THEN UPDATE SET...<br> WHEN NOT MATCHED THEN INSERT... → 단일 쿼리로 INSERT/UPDATE 동시 처리 가능 |
| 조건부 UPSERT | WHEN MATCHED AND s.status='active' THEN UPDATE...<br> WHEN MATCHED AND s.status='expired' THEN DELETE... → 조건에 따라 UPDATE/DELETE/INSERT 액션 분기 처리 |
| 성능 최적화 가능 | - 테이블 풀 스캔 방지 |
주의사항
- MERGE는 DELETE도 처리 가능하지만, 사용 시 주의 필요
- 트리거나 제약조건이 있는 테이블에서는 충돌 가능성 있음
- 대상 테이블과 원본 테이블은 충분히 식별 가능한 기준 컬럼으로 JOIN 해야 함
9일차 - SQL 활용
Oracle SQL과 ANSI SQL의 차이
Oracle SQL vs ANSI
| 항목 | 설명 |
|---|---|
| Oracle SQL | Oracle Database에 최적화된 전용 SQL 문법 스타일 |
| ANSI SQL | 국제 표준화된 SQL 문법으로, 다양한 DBMS에서 공통적으로 사용하는 방식 |
| 차이점 발생 | 주로 JOIN 문법, 시퀀스 사용법, 함수명 등에서 차이 |
JOIN 문법 차이점
Oracle 스타일
SELECT e.EMP_NAME, d.DEPT_NAME
FROM EMPLOYEE e
, DEPARTMENT d
WHERE e.DEPT_ID = d.DEPT_ID;
ANSI SQL 스타일 (표준 Join)
SELECT e.EMP_NAME, d.DEPT_NAME
FROM EMPLOYEE e
JOIN DEPARTMENT d
ON e.DEPT_ID = d.DEPT_ID;
- Oracle 스타일은 WHERE절에서 조인을 처리
- ANSI 스타일은 JOIN절을 명시적으로 사용 (가독성 좋고 유지보수 용이)
OUTER JOIN
Oracle 스타일
SELECT e.EMP_NAME, d.DEPT_NAME FROM EMPLOYEE e, DEPARTMENT d WHERE e.DEPT_ID = d.DEPT_ID(+);
- (+) 기호는 Oracle 전용 문법입니다 (우측 테이블 기준 OUTER JOIN)
ANSI SQL 스타일
SELECT e.EMP_NAME, d.DEPT_NAME FROM EMPLOYEE e LEFT JOIN DEPARTMENT d ON e.DEPT_ID = d.DEPT_ID;
- LEFT JOIN, RIGHT JOIN 명시적으로 사용 (ANSI)
시퀀스를 사용한 INSERT
Oracle 스타일
INSERT INTO CUSTOMER (ID, NAME) VALUES (CUSTOMER_SEQ.NEXTVAL, '홍길동');
Oracle은 시퀀스명.NEXTVAL 방식으로 고유값을 생성합니다.
ANSI SQL 스타일
- ANSI SQL에는 직접적인 NEXTVAL 문법이 없고, 일반적으로 IDENTITY 또는 AUTO_INCREMENT 사용을 다른 DBMS에서 지원합니다.
(Oracle에서 표준 방식처럼 하려면 IDENTITY 컬럼 사용)
-- Oracle 12c 이상에서 ANSI 스타일 유사하게 사용하는 경우 CREATE TABLE CUSTOMER ( ID NUMBER GENERATED ALWAYS AS IDENTITY, NAME VARCHAR2(100) );
Oracle SQL vs ANSI SQL 요점 정리
| 항목 | Oracle SQL 스타일 | ANSI SQL 스타일 |
|---|---|---|
| INNER JOIN | SELECT * FROM emp e, dept d WHERE e.dept_id = d.dept_id; | SELECT * FROM emp e JOIN dept d ON e.dept_id = d.dept_id; |
| OUTER JOIN | SELECT * FROM emp e, dept d WHERE e.dept_id = d.dept_id(+); | SELECT * FROM emp e LEFT JOIN dept d ON e.dept_id = d.dept_id; |
| 시퀀스 사용 | INSERT INTO customer (id) VALUES (customer_seq.NEXTVAL); | -- Oracle 12c 이상: GENERATED AS IDENTITY 사용 |
| 조인 표현 방식 | WHERE절 중심 조인 | JOIN절 중심 명시적 조인 |
| 가독성 및 유지보수 | 복잡한 조인일수록 해석 어려움 | 구조적이고 읽기 쉬움 |
- Oracle SQL: Oracle에 특화된 문법. 속도, 유연성 좋지만 이식성이 낮음.
- ANSI SQL: 표준 SQL. 다양한 DBMS와 호환되며 유지보수가 용이함.
- 신규 개발이나 협업 환경에서는 ANSI SQL 권장.
10일차 - SQL 활용
Oracle 에서 SQL이 실행될 때 내부적으로 어떤 단계들을 거치는지 단계별로 하나씩 설명드릴게요.
Oracle SQL 실행 단계
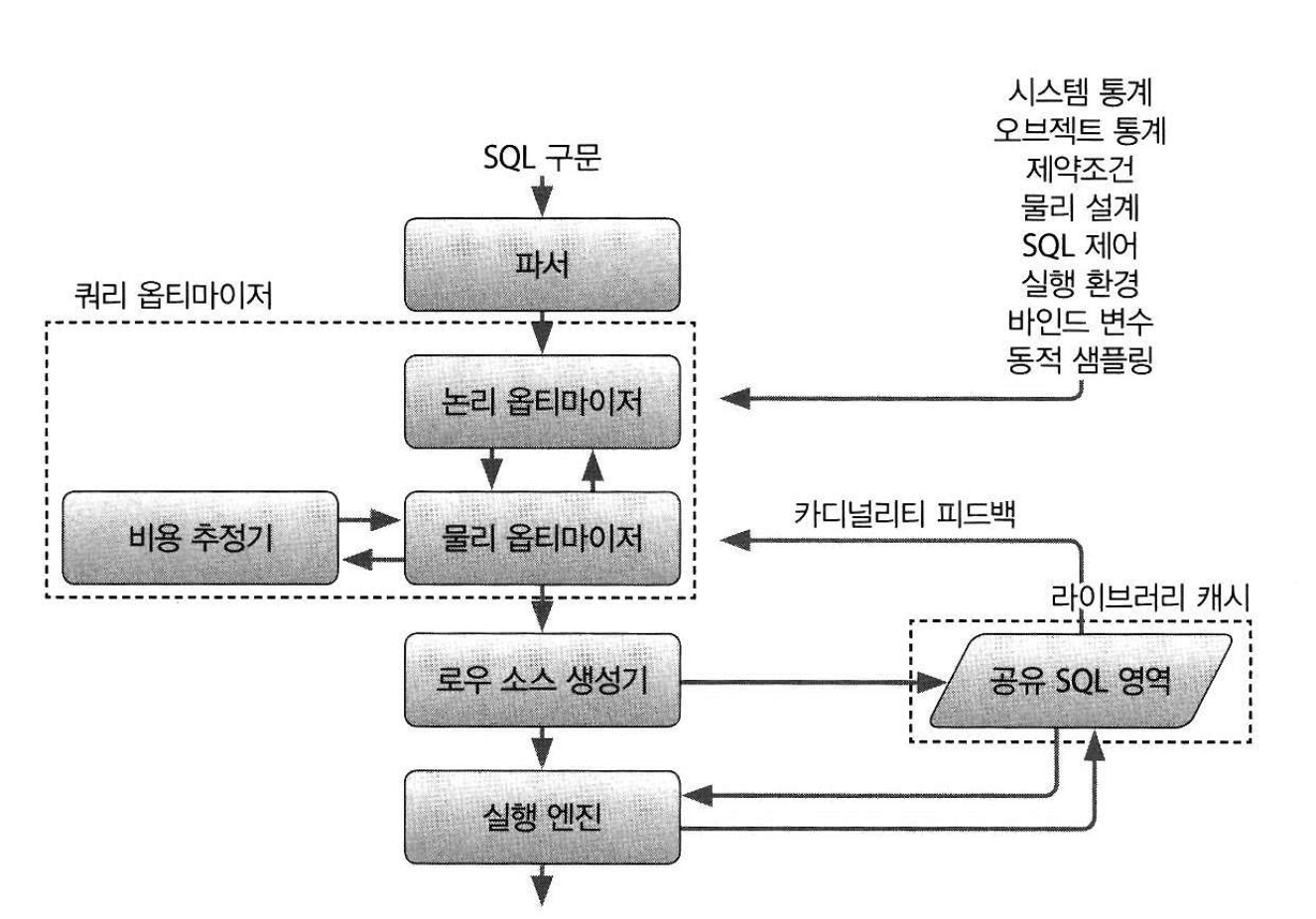
- 단계별 용어 설명
| 용어 | 설명 |
|---|---|
| SQL | Structured Query Language. 오라클 DB에 명령을 내리는 언어. 예: SELECT, INSERT, UPDATE, DELETE |
| 파싱 (Parsing) | SQL 문을 분석하여 문법 검사 및 필요한 객체(테이블, 컬럼 등) 확인. 실행 계획 재사용 여부도 판단 |
| 하드 파싱 (Hard Parse) | 이전에 실행된 적 없는 새로운 SQL일 때, 처음부터 실행 계획을 다시 만드는 작업. 성능 부담이 큼 |
| 소프트 파싱 (Soft Parse) | 같은 SQL 문이 이미 실행된 적이 있을 때, 기존 실행 계획을 재사용함. 속도가 빠름 |
| 바인드 변수 (Bind Variable) | SQL 안에서 값 대신 사용하는 변수. 예: `:id`. 성능과 보안에 좋음 |
| 옵티마이저 (Optimizer) | SQL을 가장 빠르고 효율적으로 실행하기 위해 최적의 실행계획을 만드는 엔진 |
| 실행 계획 (Execution Plan) | 옵티마이저가 만든 SQL 실행 방법의 설계도. 어떤 인덱스를 쓸지, 어떤 순서로 처리할지 결정 |
| 커서 (Cursor) | SQL 실행 결과를 저장하고, 그 결과를 한 행씩 처리하기 위한 메모리 영역 |
| 페칭 (Fetching) | SELECT 결과를 한 행씩 가져오는 작업 |
| DML | Data Manipulation Language. 데이터를 다루는 명령어: INSERT, UPDATE, DELETE, SELECT 등 |
| DDL | Data Definition Language. 데이터 구조를 정의하는 명령어: CREATE, ALTER, DROP 등 |
SQL 실행시 오라클 처리 절차
- 사용자가 SQL 문을 보냄
- • 사용자가 SELECT * FROM employees; 같은 SQL 문을 작성해서 Oracle DB에 보냅니다.
- 파싱(Parsing)
- • 오라클이 이 SQL 문장을 문법적으로 맞는지 확인하고,
- • 어떤 테이블, 컬럼, 권한을 쓰는지 체크합니다.
- • 만약 같은 SQL 문이 이전에 실행된 적이 있다면, 기존 결과(실행계획)를 재사용할 수 있습니다. (이를 Soft Parse라고 함)
- • 처음 실행이거나 다른 SQL이면 새로운 계획을 짭니다. (이를 Hard Parse라고 함)
- 바인딩(Bind)
- • SQL 문 안에 변수가 있다면 (WHERE id = :1 같은), 여기에 실제 값을 넣습니다.
- • 주로 애플리케이션에서 사용하는 기능입니다.
- 최적화(Optimization)
- • SQL이 효율적으로 실행되도록 가장 빠른 실행 방법(실행계획, Execution Plan)을 계산합니다.
- • 예: 인덱스를 쓸까? 테이블 전체를 읽을까?
- 실행(Execution)
- • 실제로 데이터를 읽거나 쓰는 작업이 시작됩니다.
- • 예: 테이블에서 필요한 행을 찾아서 읽습니다.
- 결과 반환(Fetching)
- • 실행된 결과를 한 줄씩 사용자에게 돌려줍니다.
- • 예: SELECT면 결과 행을 돌려주고,
- • INSERT, UPDATE, DELETE면 몇 개 행이 영향을 받았는지 알려줍니다.
- 실행 흐름 요약
- 단계 설명
| 단계 | 설명 |
|---|---|
| 1. SQL 전송 | 사용자가 SQL 문을 Oracle DB에 보냄 |
| 2. 파싱 (Parsing) | SQL 문법 검사, 필요한 테이블/컬럼/권한 확인. 이전 실행 계획이 있으면 재사용 (Soft Parse), 없으면 새로 생성 (Hard Parse) |
| 3. 바인딩 (Binding) | 변수(SQL 바인드 변수)에 실제 값을 연결. 주로 애플리케이션에서 사용 |
| 4. 최적화 (Optimization) | 가장 효율적인 실행 방법(실행계획)을 계산. 인덱스 사용 여부 등 결정 |
| 5. 실행 (Execution) | 실제 데이터 조회 또는 변경 작업 수행 |
| 6. 결과 반환 (Fetching) | 결과를 사용자에게 반환. SELECT는 결과 행 반환, DML(INSERT, UPDATE, DELETE)은 처리된 행 수 반환 |
EXPLAIN PLAN이란?
- SQL 문이 어떻게 실행될 예정인지 보여주는 계획표입니다.
- 인덱스를 쓸지, 테이블을 어떻게 읽을지 등을 확인할 수 있어 성능 튜닝에 매우 중요합니다.
- 실행 결과를 알려주는 건 아니고, 실행 “전”에 Oracle이 세운 실행 전략을 보여줍니다.
사용 방법
1단계: PLAN_TABLE 준비 (보통 기본 제공됨)
@?/rdbms/admin/utlxplan.sql
- 한 번만 실행하면 됩니다. PLAN_TABLE이라는 테이블이 생성됩니다.
2단계: 실행 계획 수집
EXPLAIN PLAN FOR SELECT * FROM employees WHERE department_id = 10;
3단계: 실행 계획 보기
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
3. 예제
EXPLAIN PLAN FOR SELECT first_name FROM employees WHERE employee_id = 100; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
4.요약
| 단계 | 설명 | 예제 |
|---|---|---|
| 1. PLAN_TABLE 생성 | 실행 계획을 저장할 테이블 생성 (한 번만 실행하면 됨) | @?/rdbms/admin/utlxplan.sql |
| 2. EXPLAIN PLAN 실행 | 특정 SQL 문에 대한 실행 계획을 저장 | EXPLAIN PLAN FOR SELECT * FROM employees; |
| 3. 실행 계획 조회 | 저장된 실행 계획을 확인 | SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); |
SQL 실행 계획을 해석하는 법
- 실행 계획(Execution Plan) 해석 - 주요 용어와 의미
| 실행 방식 | 설명 | 성능 특징 |
|---|---|---|
| TABLE ACCESS FULL | 테이블 전체를 처음부터 끝까지 읽음 | 느릴 수 있음 (행이 많을수록 비효율적) |
| TABLE ACCESS BY INDEX ROWID | 인덱스로 찾은 후, 해당 행을 테이블에서 읽음 | 보통 빠름 (인덱스를 쓰기 때문에) |
| INDEX UNIQUE SCAN | 인덱스에서 정확히 하나의 값을 빠르게 찾음 (PK 또는 Unique Index) | 매우 빠름 |
| INDEX RANGE SCAN | 인덱스에서 범위 조건(>, <, BETWEEN 등)으로 여러 값을 검색 | 빠름 |
| INDEX FULL SCAN | 전체 인덱스를 처음부터 끝까지 읽음 (WHERE 절 없이 인덱스 컬럼만 SELECT할 때 등) | 테이블보다 빠를 수 있음 |
| NESTED LOOPS | 작은 테이블 기준으로 반복해서 다른 테이블을 조회 | 소량의 데이터에 적합 |
| HASH JOIN | 두 테이블을 해시 테이블로 결합하여 조인 | 대량의 데이터 조인에 적합 |
| MERGE JOIN | 정렬된 두 테이블을 병합하면서 조인 | 정렬된 데이터 조인 시 효율적 |
해석 예시
EXPLAIN PLAN FOR SELECT first_name FROM employees WHERE employee_id = 100; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
결과 예:
| Id | Operation | Name | |----|-----------------------------|------------| | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | | 2 | INDEX UNIQUE SCAN | EMP_EMP_ID_PK |
해석:
- INDEX UNIQUE SCAN: PK 인덱스를 사용해 employee_id = 100을 빠르게 찾음
- TABLE ACCESS BY INDEX ROWID: 인덱스로 찾은 위치를 바탕으로 테이블에서 실제 데이터를 읽음
이런 식으로 계획을 보면 인덱스를 잘 사용하고 있는지, 전체 테이블을 읽는 불필요한 작업은 없는지 판단할 수 있어요.
11일차 - 최적의 SQL 작성법
12일차 - 서브쿼리
13일차 - 원도우 함수
윈도우 함수란?
- 일반적인 집계 함수(SUM, AVG, COUNT, 등)는 여러 행을 하나로 집계합니다.
- 윈도우 함수는 집계를 하되, 각 행마다 결과를 계산해서 반환합니다.
- OVER() 절을 사용하며, PARTITION BY, ORDER BY, ROWS BETWEEN 등을 조합하여 정교한 분석이 가능합니다.
- 결론: 모든 분석 함수는 윈도우 함수의 한 종류입니다. Oracle에서는 둘을 거의 같은 의미로 사용합니다.
- 분석 함수 (Analytic Function) : Oracle에서 제공하는 특수한 SQL 함수로, OVER() 절을 통해 행의 집합(Window)에 대해 계산함
- 윈도우 함수 (Window Function) : SQL 표준에서 정의한 개념으로, OVER() 절을 사용하는 모든 함수를 가리킴
- 순위 함수: RANK(), DENSE_RANK(), ROW_NUMBER()
- 누적 함수: SUM(), AVG(), COUNT(), MAX(), MIN() with OVER()
- 시차 함수: LAG(), LEAD()
- 분포 함수: NTILE(), PERCENT_RANK(), CUME_DIST()
- 통계 함수: FIRST_VALUE(), LAST_VALUE()
- 모두 OVER() 절을 동반해야 "분석 함수"로 동작합니다.
구문 기본 형태
<함수명>(컬럼) OVER ( PARTITION BY ... -- 그룹핑 기준 ORDER BY ... -- 정렬 기준 ROWS BETWEEN ... -- 분석 범위 )
대표적인 윈도우 함수 목록
| 함수명 | 설명 | 예제 SQL | 설명 결과 |
|---|---|---|---|
| ROW_NUMBER() | 파티션 내 행 번호를 순서대로 부여 | SELECT EMP_NAME
, ROW_NUMBER() OVER (PARTITION BY DEPT_ID
ORDER BY SALARY DESC) AS RN
FROM EMPLOYEE;
|
각 부서별 급여 내림차순 순위 (중복 순위 없음) |
| RANK() | 동점자에게 같은 순위를 부여하고 다음 순위는 건너뜀 | SELECT EMP_NAME
, RANK() OVER (PARTITION BY DEPT_ID
ORDER BY SALARY DESC) AS RANK
FROM EMPLOYEE;
|
부서 내 급여 순위 (동점자 동일 순위) |
| DENSE_RANK() | RANK와 비슷하지만 순위를 건너뛰지 않음 |
SELECT EMP_NAME
, DENSE_RANK() OVER (PARTITION BY DEPT_ID
ORDER BY SALARY DESC) AS DRANK
FROM EMPLOYEE;
|
순위에 공백 없이 채워짐 |
| LAG() | 현재 행 기준 이전 행의 값을 가져옴 |
SELECT EMP_NAME, SALARY
, LAG(SALARY) OVER (ORDER BY EMP_ID) AS PREV_SAL
FROM EMPLOYEE;
|
이전 직원의 급여 정보 확인 |
| LEAD() | 현재 행 기준 다음 행의 값을 가져옴 |
SELECT EMP_NAME, SALARY
, LEAD(SALARY) OVER (ORDER BY EMP_ID) AS NEXT_SAL
FROM EMPLOYEE;
|
다음 직원의 급여 정보 확인 |
| SUM(), AVG(), COUNT(), MAX(), MIN() | 집계 함수도 윈도우와 함께 사용 가능 | SELECT EMP_NAME, SALARY
, AVG(SALARY) OVER (PARTITION BY DEPT_ID) AS AVG_SAL
FROM EMPLOYEE;||부서별 평균 급여 | |
| FIRST_VALUE(), LAST_VALUE() | 파티션 내 정렬 기준 첫/마지막 값 반환 | SELECT EMP_NAME, SALARY
, FIRST_VALUE(SALARY) OVER (PARTITION BY DEPT_ID
ORDER BY SALARY DESC) AS TOP_SAL
FROM EMPLOYEE;
|
부서별 최고 급여 |
⸻
예제: 누적합(Cumulative Sum)
SELECT EMP_NAME, SALARY,
SUM(SALARY) OVER (PARTITION BY DEPT_ID ORDER BY SALARY) AS CUM_SAL
FROM EMPLOYEE;
부서별 급여 누적합을 계산합니다.
⸻
윈도우 프레임 옵션
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
| 의미 | 설명 |
|---|---|
| UNBOUNDED PRECEDING | 현재 파티션의 맨 처음부터 시작하는 윈도우 범위 지정 (예: 파티션 시작 ~ 현재 행까지 누적 계산 시 사용) |
| CURRENT ROW | 현재 행까지만 포함하는 윈도우 범위 지정 (예: 이동 평균 계산 시 행 단위 제한) |
| 1 PRECEDING, 1 FOLLOWING | 현재 행을 기준으로 앞뒤 1행씩 포함한 범위 지정 (예: 3행 이동 평균 계산 시 사용) |
예:
SUM(SALARY) OVER ( PARTITION BY DEPT_ID ORDER BY SALARY ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW )
부서별로 급여 순으로 정렬하고, 현재 행까지 누적된 급여 합계를 구합니다.
실무 예제 1: 부서별 상위 3위 급여 직원 조회
SELECT * FROM ( SELECT EMP_ID, EMP_NAME, DEPT_ID, SALARY, RANK() OVER (PARTITION BY DEPT_ID ORDER BY SALARY DESC) AS SAL_RANK FROM EMPLOYEE ) WHERE SAL_RANK <= 3;
각 부서별로 급여 순위를 매긴 뒤, 상위 3명의 직원만 필터링합니다.
실무 활용: 팀별 Top Performer 조회 등
실무 예제 2: 직전과의 급여 변화량 분석
SELECT EMP_ID, EMP_NAME, SALARY, LAG(SALARY) OVER (PARTITION BY DEPT_ID ORDER BY HIRE_DATE) AS PREV_SAL, SALARY - LAG(SALARY) OVER (PARTITION BY DEPT_ID ORDER BY HIRE_DATE) AS DIFF_SAL FROM EMPLOYEE;
부서 내 입사일 기준으로 정렬하여 직전 직원과 급여 차이를 분석합니다.
실무 활용: 급여 갭 파악, 트렌드 분석 등
실무 예제 3: 부서별 누적 인건비 계산
SELECT EMP_ID, EMP_NAME, DEPT_ID, SALARY, SUM(SALARY) OVER (PARTITION BY DEPT_ID ORDER BY HIRE_DATE ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS CUM_SALARY FROM EMPLOYEE;
입사일 기준으로 누적 급여를 계산합니다.
실무 활용: 연속적인 비용 추적, 월별 누적 등
실무 예제 4: 최초 입사자 정보 함께 보여주기 (FIRST_VALUE)
SELECT EMP_ID, EMP_NAME, DEPT_ID, HIRE_DATE, FIRST_VALUE(EMP_NAME) OVER (PARTITION BY DEPT_ID ORDER BY HIRE_DATE) AS FIRST_JOINED FROM EMPLOYEE;
각 부서에서 가장 먼저 입사한 직원의 이름을 모든 직원에게 보여줍니다.
실무 활용: 리더, 시니어 직원 분석 등
실무 예제 5: 부서 내 직원 수 대비 자신의 비율 (비율 분석)
SELECT EMP_ID, EMP_NAME, DEPT_ID, COUNT(*) OVER (PARTITION BY DEPT_ID) AS DEPT_TOTAL, 1.0 / COUNT(*) OVER (PARTITION BY DEPT_ID) AS RATIO FROM EMPLOYEE;
각 직원이 부서 인원 중 차지하는 비율을 계산합니다.
실무 활용: KPI 가중치, 구성비 분석 등
이 외에도, 윈도우 함수는 보고서, 통계 분석, SLA 계산, 재고 흐름 추적 등 다양한 실무 시나리오에 활용됩니다.
요점 정리
• 윈도우 함수는 분석용 SQL에서 매우 중요합니다. • OVER() 절로 집계 범위를 제한하며, 집계 결과를 각 행에 붙여서 반환합니다. • RANK, ROW_NUMBER, LAG/LEAD, FIRST_VALUE 등 다양하게 활용 가능합니다.
14일차 - 그룹 함수
- Oracle SQL에서 그룹 함수(Group Functions)는 여러 행(Row)의 값을 그룹으로 묶어 하나의 결과 값으로 요약할 때 사용하는 함수입니다.
- 주로 GROUP BY절과 함께 사용되며, 집계 함수(Aggregate Functions)라고도 부릅니다.
Oracle의 주요 그룹 함수 종류
| 함수명 | 설명 | 예제 SQL | 결과 예시 |
|---|---|---|---|
| COUNT() | 행 수를 셉니다 (NULL 제외) | SELECT COUNT(*) FROM EMPLOYEE; | 전체 직원 수 |
| SUM() | 숫자 컬럼의 합을 구합니다 | SELECT SUM(SALARY) FROM EMPLOYEE; | 전체 급여 합계 |
| AVG() | 평균 값을 계산합니다 | SELECT AVG(SALARY) FROM EMPLOYEE; | 평균 급여 |
| MAX() | 최댓값을 반환합니다 | SELECT MAX(SALARY) FROM EMPLOYEE; | 최고 급여 |
| MIN() | 최솟값을 반환합니다 | SELECT MIN(SALARY) FROM EMPLOYEE; | 최저 급여 |
| STDDEV() | 표준 편차를 구합니다 | SELECT STDDEV(SALARY) FROM EMPLOYEE; | 급여 분산도 |
| VARIANCE() | 분산을 구합니다 | SELECT VARIANCE(SALARY) FROM EMPLOYEE; | 급여 분산 값 |
주의할 점
- NULL은 무시되는 함수가 많습니다 (COUNT(col), SUM(col), AVG(col) 등)
- GROUP BY에서 사용되지 않은 컬럼은 SELECT에 단독으로 쓸 수 없습니다.
- 단일 결과를 원할 경우 GROUP BY 없이 사용할 수 있습니다.
예제
기본 예제
SELECT COUNT(*) AS TOTAL_EMPLOYEES,
SUM(SALARY) AS TOTAL_SALARY,
AVG(SALARY) AS AVG_SALARY,
MAX(SALARY) AS MAX_SALARY,
MIN(SALARY) AS MIN_SALARY
FROM EMPLOYEE;
EMPLOYEE 테이블의 직원 수, 급여 합계, 평균, 최고/최저 급여를 한 번에 출력합니다.
GROUP BY와 함께 사용하는 예제
SELECT DEPT_ID,
COUNT(*) AS EMP_COUNT,
AVG(SALARY) AS AVG_SALARY
FROM EMPLOYEE
GROUP BY DEPT_ID;
부서별로 직원 수와 평균 급여를 계산합니다.
HAVING 절로 그룹 조건 추가
WHERE는 행 필터링, HAVING은 그룹 필터링에 사용합니다.
SELECT DEPT_ID,
COUNT(*) AS EMP_COUNT
FROM EMPLOYEE
GROUP BY DEPT_ID
HAVING COUNT(*) >= 5;
직원 수가 5명 이상인 부서만 조회합니다.
고급 기능 및 실무 예제
▶ 예제 1: 평균 이상 급여 직원 조회
SELECT * FROM EMPLOYEE WHERE SALARY > ( SELECT AVG(SALARY) FROM EMPLOYEE );
서브쿼리를 통해 전체 평균보다 높은 급여를 받는 직원을 조회합니다.
▶ 예제 2: 월별 매출 요약
SELECT TO_CHAR(SALE_DATE, 'YYYY-MM') AS 월, SUM(SALE_AMOUNT) AS 월매출, COUNT(*) AS 거래건수 FROM SALES GROUP BY TO_CHAR(SALE_DATE, 'YYYY-MM') ORDER BY 월;
TO_CHAR()로 날짜를 월 단위로 변환해 그룹핑합니다.
▶ 예제 3: 부서별 최고 급여자 정보
SELECT * FROM EMPLOYEE E WHERE (E.DEPT_ID, E.SALARY) IN ( SELECT DEPT_ID, MAX(SALARY) FROM EMPLOYEE GROUP BY DEPT_ID );
서브쿼리로 부서별 최고 급여를 구하고, 그 조건에 맞는 직원 정보 추출합니다.
▶ 예제 4: 비율(%) 분석
SELECT DEPT_ID, COUNT(*) AS 직원수, ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (), 2) AS 비율 FROM EMPLOYEE GROUP BY DEPT_ID;
전체에서 해당 그룹이 차지하는 **구성비(%)**를 계산합니다.
SUM(...) OVER ()는 전체 합계를 구할 때 사용하는 윈도우 함수입니다.
▶ 예제 5: 다중 집계 GROUPING SETS, ROLLUP, CUBE
-- ROLLUP: 부서별 + 전체 합계 SELECT DEPT_ID, JOB_ID, SUM(SALARY) AS 합계 FROM EMPLOYEE GROUP BY ROLLUP(DEPT_ID, JOB_ID); -- CUBE: 모든 조합(부서, 직무별 합계, 전체 합계 포함) SELECT DEPT_ID, JOB_ID, SUM(SALARY) AS 합계 FROM EMPLOYEE GROUP BY CUBE(DEPT_ID, JOB_ID); -- GROUPING SETS: 원하는 조합만 집계 SELECT DEPT_ID, JOB_ID, SUM(SALARY) AS 합계 FROM EMPLOYEE GROUP BY GROUPING SETS ( (DEPT_ID), (JOB_ID), () );
복잡한 다차원 집계가 필요한 리포트에 활용됩니다.
요점 정리
| 기능명 | 설명 | 예제 구문 |
|---|---|---|
| GROUP BY | 컬럼 기준으로 행을 그룹화 | SELECT DEPT_ID, AVG(SALARY) FROM EMPLOYEE GROUP BY DEPT_ID; |
| HAVING | 그룹 조건 필터링 | ... HAVING COUNT(*) > 5; |
| ROLLUP | 소계, 총계 계산 | GROUP BY ROLLUP(DEPT_ID, JOB_ID) |
| CUBE | 다차원 집계 (모든 조합) | GROUP BY CUBE(DEPT_ID, JOB_ID) |
| GROUPING SETS | 특정 조합만 집계 | GROUP BY GROUPING SETS ((DEPT_ID), (JOB_ID), ()) |
| 비율 계산 | 전체 대비 그룹 비율 | COUNT(*) * 100 / SUM(COUNT(*)) OVER () |
15일차 - 인덱스
- 책에 비유하면?
- 책에서 특정 단어를 찾을 때 “찾아보기(색인)” 를 이용하죠?
- 오라클의 인덱스도 같은 역할을 해요.
- 데이터를 빠르게 찾기 위해 정리된 목록(색인표) 을 만들어 놓는 거예요.
왜 인덱스가 필요할까?
| 상황 | 인덱스 없음 | 인덱스 있음 |
|---|---|---|
SELECT * FROM employees WHERE name = 'Kim'; |
전체 테이블을 처음부터 끝까지 검사함 ▸ Full Table Scan 발생 |
인덱스를 따라 바로 'Kim'의 위치로 감 ▸ Index Range Scan 동작 |
결과: 인덱스가 있으면 훨씬 빠릅니다!
인덱스의 기본 종류
| 인덱스 종류 | 설명 | 특징 |
|---|---|---|
| B-tree 인덱스 | 가장 일반적인 인덱스 | 빠르고 대부분의 검색에 적합 |
| Unique 인덱스 | 중복을 허용하지 않는 인덱스 (PK 같은 경우) | 중복 데이터 방지 |
| Composite 인덱스 | 여러 컬럼을 묶어서 만든 인덱스 | WHERE 절에 여러 컬럼이 있을 때 효과적 |
| Bitmap 인덱스 | 값의 종류가 적은 컬럼에 적합 (예: 성별) | 주로 DW(데이터 웨어하우스)에서 사용 |
| Function-Based 인덱스 | 계산 결과에 대해 인덱스를 만듦 (예: `UPPER(name)`) | 함수가 들어간 WHERE 절에도 인덱스 사용 가능 |
인덱스는 자동으로 생길까?
- Primary Key 또는 Unique 제약 조건을 만들면 Oracle이 자동으로 인덱스를 생성해줘요.
- 그 외에는 사용자가 직접 CREATE INDEX 문으로 만들어야 해요.
인덱스 만들기 예시
CREATE INDEX idx_emp_name ON employees(name);
인덱스가 항상 좋은 건 아닐까?
- 읽기 성능은 좋아지지만,데이터를 INSERT, UPDATE, DELETE 할 때는 인덱스도 같이 수정돼야 하므로 부하가 생깁니다.
- 그래서 필요한 컬럼에만 신중하게 인덱스를 만들어야 해요.
인덱스 고급 기능
1. Function-Based Index (함수 기반 인덱스)
설명
- SQL에서 WHERE UPPER(name) = 'KIM' 같이 함수가 쓰이면 일반 인덱스는 사용 못 해요.
- 이럴 때, 함수의 결과에 인덱스를 미리 만들어두면 성능 향상 가능!
예시
CREATE INDEX idx_upper_name ON employees(UPPER(name));
2. Invisible Index (보이지 않는 인덱스)
설명
- 인덱스를 일시적으로 비활성화해서, 쿼리가 인덱스를 쓰지 않도록 설정.
- 성능 테스트할 때 아주 유용해요.
예시
ALTER INDEX idx_emp_name INVISIBLE; -- 인덱스 감추기 ALTER INDEX idx_emp_name VISIBLE; -- 다시 보이게 하기
3. Partial Index (부분 인덱스) - Oracle 12c부터는 Zone Maps로 유사 기능
설명
- 조건에 따라 일부 행에만 인덱스 생성 (일반적으로는 파티션 인덱스로 구현)
- 예: 2020년 이후 데이터만 인덱스 적용
4. Descending Index (내림차순 인덱스)
설명
- 정렬이 많은 컬럼에 대해 ORDER BY column DESC 쿼리 성능 향상
예시
CREATE INDEX idx_emp_salary_desc ON employees(salary DESC);
5. Compressed Index (압축 인덱스)
설명
- 중복되는 인덱스 키가 많은 경우, 공간 절약과 읽기 성능 향상 효과
- 특히 Composite Index(다중 컬럼 인덱스)에 유리
예시
CREATE INDEX idx_comp ON emp(dept_id, job_id) COMPRESS;
6. Index on Virtual Columns (가상 컬럼 인덱스)
설명
- 테이블에는 없지만 계산 결과로 만들어지는 가상 컬럼에도 인덱스를 생성할 수 있어요.
예시
ALTER TABLE emp
ADD (full_name AS (first_name || ' ' || last_name));
CREATE INDEX idx_fullname
ON emp(full_name);
7. Global vs Local Partitioned Index
설명
- 파티션 테이블에 인덱스를 만들 때,
- Global Index: 전체 테이블 기준 하나의 인덱스
- Local Index: 각 파티션마다 따로 인덱스 생성 (DML 변경 시 유지가 쉬움)
8. Online Index Operations
설명
- Oracle 19c에서는 DML 중에도 인덱스를 생성하거나 재구성 가능
- 서비스 중단 없이 작업 가능 (Enterprise Edition 기준)
예시
CREATE INDEX idx_emp_job ON employees(job_id) ONLINE;
요점 정리
| 고급 기능 | 설명 | 예시/비고 |
|---|---|---|
| Function-Based Index | 함수가 포함된 WHERE 절에서도 인덱스를 사용 가능 | CREATE INDEX idx_upper_name ON emp(UPPER(name)); |
| Invisible Index | 인덱스를 일시적으로 숨겨 쿼리 테스트 | ALTER INDEX idx_name INVISIBLE; |
| Descending Index | 내림차순 정렬에 맞는 인덱스 | CREATE INDEX idx_desc ON emp(salary DESC); |
| Compressed Index | 중복 키를 압축하여 공간 절약 및 성능 향상 | CREATE INDEX idx_comp ON emp(dept_id, job_id) COMPRESS; |
| Virtual Column Index | 계산된 가상 컬럼에도 인덱스 가능 | CREATE INDEX idx_virtual ON emp(full_name); |
| Global / Local Partitioned Index | 파티션 테이블 인덱스 최적화 방식 | Local은 유지관리 쉬움 |
| Online Index Create/Rebuild | 서비스 중단 없이 인덱스 작업 가능 | CREATE INDEX ... ONLINE |
16일차 - CONNECT BY 절
Oracle CONNECT BY 계층형 쿼리
오라클(Oracle) 데이터베이스에서 계층형 데이터를 조회할 때 CONNECT BY 절을 사용합니다. 트리 구조, 조직도, BOM 구조 등의 데이터를 SQL 하나로 탐색하고 출력할 수 있는 강력한 기능입니다.
이 글에서는 CONNECT BY, START WITH, LEVEL, CONNECT_BY_ROOT, CONNECT_BY_ISCYCLE, CONNECT_BY_ISLEAF, SYS_CONNECT_BY_PATH 등 계층형 SQL에서 사용하는 핵심 요소들을 예제와 함께 정리합니다.
CONNECT BY 절 구조
| 절 | 설명 |
|---|---|
| START WITH | 계층 구조의 시작점(루트 노드)을 지정 |
| CONNECT BY | 부모-자식 간 연결 조건 정의 |
| PRIOR | 연결 방향 지정 (부모 → 자식 또는 자식 → 부모) |
| ORDER SIBLINGS BY | 같은 부모를 가진 노드 간 정렬 |
예:
SELECT employee_id, manager_id, LEVEL FROM employees START WITH manager_id IS NULL CONNECT BY PRIOR employee_id = manager_id ORDER SIBLINGS BY employee_id;
PRIOR 키워드 설명
방식 설명
CONNECT BY PRIOR 자식 = 부모 부모 → 자식 (Top-down)
CONNECT BY 부모 = PRIOR 자식 자식 → 부모 (Bottom-up)
예제:
-- 순방향 전개
CONNECT BY PRIOR empno = mgr
-- 역방향 전개
CONNECT BY empno = PRIOR mgr
LEVEL 가상 컬럼
LEVEL은 계층의 깊이를 나타내는 가상 컬럼입니다. 루트 노드는 1부터 시작하며, 자식으로 갈수록 2, 3, ...으로 증가합니다.
CONNECT_BY_ROOT 함수
현재 행의 루트(시작점) 값을 반환합니다.
SELECT LEVEL, ename, CONNECT_BY_ROOT ename AS root_ename FROM emp START WITH mgr IS NULL CONNECT BY PRIOR empno = mgr;
CONNECT_BY_ISCYCLE 가상 컬럼
사이클(순환 참조)을 감지할 수 있는 가상 컬럼입니다. NOCYCLE 옵션과 함께 사용해야 하며, 순환이 감지되면 1을, 아니면 0을 반환합니다.
SELECT empno, CONNECT_BY_ISCYCLE, LEVEL FROM emp START WITH mgr IS NULL CONNECT BY NOCYCLE PRIOR empno = mgr;
CONNECT_BY_ISLEAF 가상 컬럼
해당 노드가 리프(leaf, 자식이 없는 노드)인지를 판별합니다.
SELECT empno, CONNECT_BY_ISLEAF FROM emp START WITH mgr IS NULL CONNECT BY PRIOR empno = mgr;
SYS_CONNECT_BY_PATH 함수
루트부터 현재 행까지의 경로를 구분자와 함께 문자열로 반환합니다.
SELECT empno,
SYS_CONNECT_BY_PATH(ename, ' > ') AS path
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
성능 팁
START WITH 조건 컬럼에는 인덱스가 존재해야 성능 저하를 방지할 수 있습니다.
LEVEL이 깊어질수록 비용이 증가합니다. 필요하다면 LEVEL <= n 조건을 함께 사용하세요.
DUAL CONNECT BY 형태는 조인 없이 다량의 반복 데이터를 생성할 수 있으나, 성능 이슈 발생 시 MERGE JOIN을 고려하세요.
예:
SELECT /*+ LEADING(A) USE_MERGE(B) */
COUNT (*)
FROM t1 a
, (SELECT LEVEL lv
FROM DUAL
CONNECT BY LEVEL <= 100) b
WHERE b.lv <= a.c1;
실전 예제: 테스트 테이블 생성 및 계층 쿼리
CREATE TABLE t1 (
parent_c VARCHAR2(1),
child_c VARCHAR2(1)
);
INSERT INTO t1 VALUES ('a','b');
INSERT INTO t1 VALUES ('b','c');
INSERT INTO t1 VALUES ('a','c');
INSERT INTO t1 VALUES ('c','d');
INSERT INTO t1 VALUES ('c','e');
INSERT INTO t1 VALUES ('e','f');
COMMIT;
순방향 계층 전개 (부모 → 자식):
SELECT parent_c, child_c, LEVEL FROM t1 START WITH parent_c = 'a' CONNECT BY PRIOR child_c = parent_c;
역방향 계층 전개 (자식 → 부모):
SELECT parent_c, child_c, LEVEL FROM t1 START WITH child_c = 'f' CONNECT BY child_c = PRIOR parent_c;
날짜 생성 활용 예제
1) 일자 리스트 구하기:
SELECT TO_CHAR(TO_DATE('20240101','YYYYMMDD') + LEVEL - 1, 'YYYY-MM-DD') AS day
FROM dual
CONNECT BY LEVEL <= TO_DATE('20240110','YYYYMMDD') - TO_DATE('20240101','YYYYMMDD') + 1;
2) 월별 리스트 구하기:
SELECT TO_CHAR(ADD_MONTHS(TO_DATE('202201','YYYYMM'), LEVEL-1), 'YYYY-MM') AS month
FROM dual
CONNECT BY LEVEL <= 12;
결론
- CONNECT BY는 단순한 계층 쿼리 기능을 넘어, 조직도, 트리구조, BOM, 기간 생성 등 다양한 용도로 사용되는 필수 SQL 기능입니다.
- 위에서 다룬 가상 컬럼과 성능 팁을 익히면 보다 효율적으로 데이터 구조를 탐색할 수 있습니다.
17일차 - LATERAL
LATERAL 이란?
- (영문)The LATERAL clause allows a subquery in the FROM clause to reference columns from preceding tables in the same FROM clause.
- (한글) LATERAL은 FROM 절에 있는 서브쿼리에서 같은 레벨에 있는 테이블의 컬럼을 사용할 수 있게 해주는 기능입니다.(oracle12c 이전에는 FROM절에 있는 걑은 레벨의 테이블을 같은 레벨에 있는 서브쿼리에서 사용할수 없었음)
왜 필요한가요?
- 기존에는 FROM 절의 **서브쿼리(subquery)**가 외부 테이블의 값을 참조할 수 없었어요.
- LATERAL을 쓰면 이 제한을 풀 수 있어, 행 단위로 동적으로 계산하거나 조인할 수 있어요.
기본 문법
SELECT ...
FROM 테이블1 t,
LATERAL (
SELECT ... FROM ... WHERE ... t.컬럼 ...
) A
- Oracle 12c 이상에서는 LATERAL을 쓰지 않고 CROSS APPLY 또는 **OUTER APPLY**를 쓰기도 합니다.
- Oracle에서 CROSS APPLY = LATERAL.
예제
예제 테이블
- orders
| order_id | customer_id |
|---|---|
| 1 | 100 |
| 2 | 200 |
- customers
| customer_id | name |
|---|---|
| 100 | Alice |
| 200 | Bob |
| 300 | Charlie |
목표
orders 테이블에서 각 주문에 해당하는 고객 정보를 바로 옆에서 가져오기 (JOIN도 가능하지만, LATERAL은 더 유연한 활용이 가능)
⸻
쿼리 예시
SELECT o.order_id, c.name
FROM orders o,
LATERAL (
SELECT name
FROM customers
WHERE customers.customer_id = o.customer_id
) c;
- 결과
| order_id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
⸻
5. 동적으로 N개만 가져오기 (Top-N per group)
예제: 각 고객당 최근 주문 1개만 가져오기
SELECT c.customer_id, c.name, o.order_id
FROM customers c,
LATERAL (
SELECT order_id
FROM orders
WHERE orders.customer_id = c.customer_id
ORDER BY order_id DESC
FETCH FIRST 1 ROW ONLY
) o;
⸻
6. LATERAL vs APPLY
| Oracle 구문 | 설명 |
|---|---|
| LATERAL | Oracle 12c 이상에서 사용 가능 |
| CROSS APPLY | LATERAL과 동일 (INNER JOIN) |
| OUTER APPLY | LATERAL + OUTER JOIN 느낌 (NULL 허용) |
⸻
7. 요약
항목 내용 목적 FROM 서브쿼리에서 앞의 테이블 값을 참조하고 싶을 때 사용 장점 각 행별로 동적인 서브쿼리 실행 가능 주 사용처 Top-N per group, JSON 파싱, 동적 컬럼 처리 등 필요 조건 Oracle 12c 이상
⸻
보너스: JSON 컬럼 분해에도 유용!
SELECT t.id, j.*
FROM my_table t,
JSON_TABLE(t.json_col, '$[*]'
COLUMNS (name VARCHAR2(100) PATH '$.name',
age NUMBER PATH '$.age')) j;
위 예제처럼 JSON_TABLE도 LATERAL처럼 동작합니다.
⸻
실전 시나리오(예: JSON 배열 쪼개기, 시간대별 계산, 조건별 행 생성 등)
18일차 - 정규표현식(regular expression)
Oracle 19c에서 사용하는 정규표현식 패턴
정규표현식 기초 설명 (Oracle 기준)
| 패턴 | 의미 | 쉬운 설명 | 예시 |
|---|---|---|---|
| . | 임의의 한 글자 | 어떤 글자든 한 글자만 | a.c → "abc", "axc"
|
| * | 0회 이상 반복 | 없어도 되고, 많아도 됨 | a* → "", "a", "aa", "aaa"
|
| + | 1회 이상 반복 | 적어도 한 번은 나와야 함 | a+ → "a", "aa", "aaa"
|
| ? | 0회 또는 1회 | 있을 수도, 없을 수도 있음 | ab? → "a", "ab"
|
| ^ | 문자열의 시작 | 맨 앞에서 시작해야 함 | ^a → "apple"에는 일치, "banana"에는 불일치
|
| $ | 문자열의 끝 | 맨 끝에서 끝나야 함 | ing$ → "playing", "going"
|
| [abc] | 괄호 안 문자 중 하나 | a, b, c 중 하나와 일치 | [abc] → "a", "b", "c"
|
| [^abc] | 괄호 안 문자 제외 | a, b, c를 제외한 문자와 일치 | [^abc] → "d", "x"
|
| [a-z] | 알파벳 범위 | a부터 z 중 하나 | [A-Z] → 대문자, [0-9] → 숫자
|
| {n} | 정확히 n번 반복 | 정확히 n번 반복됨 | a{3} → "aaa"
|
| {n,} | n번 이상 반복 | n번 이상 반복됨 | a{2,} → "aa", "aaa", ...
|
| {n,m} | n~m회 반복 | n 이상 m 이하 반복 | a{2,4} → "aa", "aaa", "aaaa"
|
| 또는(OR) | 둘 중 하나 | dog → "cat", "dog" | |
| \ | 이스케이프 문자 | 특수기호를 문자로 인식 | \. → 점(.) 자체
|
예시로 이해하기
'^[A-Z][a-z]+$'
→ 의미: 첫 글자는 대문자, 그 뒤는 소문자 한 글자 이상, 전체가 한 단어
- 일치: "John", "David"
- 불일치: "john", "DAVID", "John123"
^[0-9]{3}-[0-9]{4}-[0-9]{4}$
→ 의미: 전화번호 형식 (숫자3-숫자4-숫자4)
- 일치: "010-1234-5678"
- 불일치: "10-1234-5678", "01012345678"
'^\d{6}-\d{7}$'
→ 의미: 주민등록번호 형식 (6자리-7자리 숫자) → \d는 숫자 [0-9]와 같음
- 일치: "990101-1234567"
- 불일치: "9901011234567", "99-0101-1234567"
| 사용 목적 | 정규식 예시 | 설명 |
|---|---|---|
| 이메일 검증 | ^[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}$
|
|
| 전화번호 확인 | ^\d{3}-\d{3,4}-\d{4}$
|
|
| 숫자만 추출 | \d+
|
|
| 특정 문자 제거 | REGEXP_REPLACE(col, '[^0-9]', )
|
|
실전예시
2. Oracle SQL에서 사용하는 정규표현식 함수 예제
1. REGEXP_LIKE – 패턴 일치 여부 확인
SELECT first_name FROM employees WHERE REGEXP_LIKE(first_name, '^A'); -- 이름이 A로 시작하는 직원
2. REGEXP_SUBSTR – 패턴에 맞는 부분 문자열 추출
SELECT REGEXP_SUBSTR('john.doe@example.com', '[a-z0-9._%+-]+') AS local_part
FROM dual;
-- 결과: 'john.doe'
3. REGEXP_INSTR – 패턴 위치 찾기
SELECT REGEXP_INSTR('employee123data', '[0-9]+') AS number_pos
FROM dual;
-- 결과: 9 (숫자가 처음 나오는 위치)
4. REGEXP_REPLACE – 패턴에 맞는 문자열 치환
SELECT REGEXP_REPLACE('abc123xyz', '[0-9]', '') AS removed_digits''
FROM dual;
-- 결과: 'abcxyz' (숫자 제거)
5. 전화번호 형식 확인
SELECT phone_number
FROM customers
WHERE REGEXP_LIKE(phone_number, '^\d{3}-\d{3,4}-\d{4}$');
-- 예: '010-1234-5678' 형식만 조회
실무에 유용한 정규식 활용법
1. 이메일 주소 유효성 검사
SELECT email
FROM users
WHERE REGEXP_LIKE(email, '^[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}$', 'i');
- 설명: @ 앞뒤 형식을 체크하고, 대소문자 구분 없이 검사 ('i' 플래그)
- 일치: user123@gmail.com, test.name@domain.co.kr
2. 주민등록번호 유효성 패턴 확인
SELECT ssn
FROM people
WHERE REGEXP_LIKE(ssn, '^\d{6}-\d{7}$');
- 설명: 주민번호 형식 ######-####### 검사
- 일치: 990101-1234567
3. 주민등록번호 마스킹 처리 (정규식 + 치환)
SELECT REGEXP_REPLACE(ssn, '(\d{6})-(\d{7})', '\1-*******') AS masked_ssn
FROM people;
- 결과: 990101-*******
4. 문자열에서 숫자만 추출
SELECT REGEXP_SUBSTR('abc123def456', '\d+') AS first_number
FROM dual;
- 결과: 123 (첫 번째 숫자 그룹 추출)
5. 특정 패턴이 포함된 문자열만 추출 (예: http 또는 https로 시작하는 URL)
SELECT REGEXP_SUBSTR('Visit https://example.com now', 'https?://[^\s]+') AS url
FROM dual;
6. 정규표현식으로 공백/특수문자 제거
SELECT REGEXP_REPLACE('hello! @world#2024', '[^a-zA-Z0-9]', '') AS clean_string''
FROM dual;
- 결과: helloworld2024
7. 특정 문자로 시작하거나 끝나는 문자열 필터링
-- 이름이 'K'로 시작하는 경우 SELECT name FROM employees WHERE REGEXP_LIKE(name, '^K'); -- 이름이 'y'로 끝나는 경우 SELECT name FROM employees WHERE REGEXP_LIKE(name, 'y$');
19일차 - PL/SQL 기초
20일차 - PL/SQL 함수]
Oracle PL/SQL 함수 설명
개념 요약
- 함수(Function)는 하나의 값을 반환하는 PL/SQL 서브프로그램입니다.
- 프로시저(Procedure)와 달리, 함수는 항상 RETURN을 통해 결과를 반환해야 하며, SQL문 안에서도 호출이 가능합니다.
주요 특징
- 반드시 하나의 값 반환
- SELECT문, WHERE절, PL/SQL 블록 등 다양한 위치에서 호출 가능
- 입력 매개변수(Parameter)를 사용할 수 있음
함수 문법
CREATE OR REPLACE FUNCTION 함수이름 ( 매개변수명 데이터타입 ) RETURN 반환타입 IS -- 변수 선언부 BEGIN -- 로직 처리 RETURN 반환값; END;
함수 설명
| 항목 | 설명 |
|---|---|
| 함수(Function) | 값을 반환하는 PL/SQL 서브프로그램 |
| 사용 목적 | 로직을 재사용하고 SQL 내에서 값 계산 |
| 반환값 필수 | RETURN 문을 통해 한 개의 값 반환 |
| 호출 위치 | SELECT, WHERE, PL/SQL 블록 등 |
| 예시 | SELECT 함수명(매개변수) FROM DUAL; |
예시
CREATE OR REPLACE FUNCTION get_tax ( p_amount NUMBER ) RETURN NUMBER IS BEGIN RETURN p_amount * 0.1; END;
사용 예시:
SELECT get_tax(1000) FROM DUAL; -- 결과: 100
oracle 내장함수
1. 날짜 및 시간 함수
| 함수명 | 설명 |
|---|---|
| SYSDATE | 현재 날짜와 시간을 반환 |
| SYSTIMESTAMP | 현재 날짜와 시간(타임존 포함)을 반환 |
| ADD_MONTHS(date, n) | 날짜에 n개월을 더함 |
| MONTHS_BETWEEN(d1, d2) | 두 날짜 사이의 개월 수 계산 |
| LAST_DAY(date) | 해당 월의 마지막 날짜 반환 |
| TRUNC(date) | 날짜의 시/분/초를 제거 (일 단위로 자름) |
| ROUND(date, 'fmt') | 날짜를 지정한 단위로 반올림 |
2. 문자 함수
| 함수명 | 설명 |
|---|---|
| UPPER(str) | 문자열을 대문자로 변환 |
| LOWER(str) | 문자열을 소문자로 변환 |
| INITCAP(str) | 각 단어의 첫 글자를 대문자로 변환 |
| LENGTH(str) | 문자열 길이 반환 |
| SUBSTR(str, start, len) | 문자열의 일부 추출 |
| INSTR(str, substr) | 부분 문자열의 시작 위치 반환 |
| REPLACE(str, old, new) | 문자열 치환 |
| TRIM(str) | 문자열 앞뒤의 공백 제거 |
3. 숫자 함수
| 함수명 | 설명 |
|---|---|
| ROUND(n, m) | 소수 m자리까지 반올림 |
| TRUNC(n, m) | 소수 m자리까지 자름 |
| MOD(n1, n2) | 나머지 반환 |
| FLOOR(n) | 이하 정수 반환 |
| CEIL(n) | 이상 정수 반환 |
| ABS(n) | 절대값 반환 |
4. 변환 함수
| 함수명 | 설명 |
|---|---|
| TO_CHAR(date/number, fmt) | 날짜나 숫자를 문자열로 변환 |
| TO_DATE(str, fmt) | 문자열을 날짜로 변환 |
| TO_NUMBER(str) | 문자열을 숫자로 변환 |
21일차 - PL/SQL 프로시져]
Oracle PL/SQL 프로시저 설명
1. 개념
- **프로시저(Procedure)**는 특정 작업을 수행하는 PL/SQL 서브프로그램입니다.
- 함수와 달리 프로시저는 값을 반환하지 않으며, 주로 반복되는 작업이나 다양한 기능을 묶어두는 데 사용됩니다.
- 입력 매개변수를 받아서 로직을 처리한 후, 결과는 출력 매개변수를 통해 반환할 수 있습니다.
2. 주요 특징
- 반환 값 없음: 프로시저는 값을 반환하지 않음.
- 매개변수 사용 가능: 입력, 출력, 입력/출력 매개변수를 사용할 수 있음.
- 다양한 용도: 데이터 수정, 트랜잭션 처리, 복잡한 로직 등을 처리할 때 사용.
3. 프로시저 문법
CREATE OR REPLACE PROCEDURE 프로시저이름 ( 매개변수명 데이터타입 [IN | OUT | IN OUT] ) IS -- 변수 선언부 BEGIN -- 로직 처리 NULL; -- 여기에 실제 처리 로직이 들어감 END;
- IN: 입력 매개변수 (값을 전달받음)
- OUT: 출력 매개변수 (값을 반환)
- IN OUT: 입력과 출력 모두 가능한 매개변수
4. 프로시저 설명
| 항목 | 설명 |
|---|---|
| 프로시저(Procedure) | 값을 반환하지 않는 PL/SQL 서브프로그램 |
| 사용 목적 | 복잡한 작업을 서브프로그램으로 캡슐화하여 재사용 가능 |
| 매개변수 | IN, OUT, IN OUT 매개변수 사용 가능 |
| 예시 | EXECUTE 프로시저명(매개변수); |
5. 프로시저 예시
CREATE OR REPLACE PROCEDURE add_employee ( p_emp_id IN NUMBER, p_name IN VARCHAR2, p_salary IN NUMBER, p_department IN VARCHAR2 ) IS BEGIN INSERT INTO employees (emp_id, name, salary, department) VALUES (p_emp_id, p_name, p_salary, p_department); COMMIT; END;
프로시저 호출 예시:
EXECUTE add_employee(101, 'John Doe', 5000, 'Sales');
6. 주요 활용 사례
- 데이터 삽입/수정: INSERT, UPDATE, DELETE 등 반복적인 데이터 조작
- 비즈니스 로직 캡슐화: 여러 SQL 문을 하나의 프로시저에 묶어서 복잡한 로직을 구현
- 에러 처리: 예외 처리 구문을 프로시저 내에서 정의하여 안정성 증가
예외 처리와 매개변수 예시
1. 예외 처리(Exception Handling)
Oracle PL/SQL 프로시저는 EXCEPTION 블록을 사용해 오류 발생 시 적절한 조치를 취할 수 있습니다.
예외 처리 포함한 프로시저 예시
CREATE OR REPLACE PROCEDURE delete_employee (
p_emp_id IN NUMBER
) IS
BEGIN
DELETE FROM employees WHERE emp_id = p_emp_id;
IF SQL%ROWCOUNT = 0 THEN
RAISE_APPLICATION_ERROR(-20001, '해당 사번의 직원이 존재하지 않습니다.');
END IF;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
DBMS_OUTPUT.PUT_LINE('오류 발생: ' || SQLERRM);
END;
특징 설명 (미디어위키 표 형식):
| 구문 | 설명 |
|---|---|
| EXCEPTION | 오류 발생 시 실행할 블록 시작 |
| WHEN OTHERS THEN | 모든 예외를 포괄적으로 처리 |
| SQLERRM | 오류 메시지 반환 |
| RAISE_APPLICATION_ERROR | 사용자 정의 오류 메시지 출력 (에러 코드 범위: -20001 ~ -20999) |
2. IN, OUT, IN OUT 매개변수 예시
예제: 직원 급여 인상 후 결과 반환
CREATE OR REPLACE PROCEDURE raise_salary ( p_emp_id IN NUMBER, p_raise_percent IN NUMBER, p_new_salary OUT NUMBER ) IS BEGIN UPDATE employees SET salary = salary + salary * p_raise_percent / 100 WHERE emp_id = p_emp_id; SELECT salary INTO p_new_salary FROM employees WHERE emp_id = p_emp_id; COMMIT; END;
호출 예시 (익명 블록 사용):
DECLARE
v_new_salary NUMBER;
BEGIN
raise_salary(101, 10, v_new_salary);
DBMS_OUTPUT.PUT_LINE('인상된 급여: ' || v_new_salary);
END;
3. 매개변수 유형 요약
| 매개변수 유형 | 설명 |
|---|---|
| IN | 호출 시 외부에서 값을 전달 (기본값) |
| OUT | 프로시저가 값을 반환하기 위해 사용 |
| IN OUT | 전달도 받고 반환도 가능 (읽기/쓰기) |
22일차 - PL/SQL 패키지
- Oracle 19c에서의 **패키지(Package)**는 관련된 **PL/SQL 객체들(프로시저, 함수, 변수 등)**을 하나로 묶어 모듈화된 구조로 제공하는 기능입니다.
- 이를 통해 코드의 재사용성, 유지보수성, 성능을 크게 향상시킬 수 있습니다.
- (영문) Package = 꾸러미, 묶음 → 관련된 기능을 한 덩어리로 묶은 논리적 단위
- (한글) 패키지 = 관련 기능들을 묶어 놓은 PL/SQL 코드 집합
특징
| 항목 | 설명 |
|---|---|
| 구성 | Specification(사양)과 Body(본문) 두 부분으로 구성됨
|
| 모듈화 | 관련 로직을 하나로 묶어 코드 관리 용이 |
| 성능 향상 | 한번 메모리에 로딩되면 여러 번 호출 가능 |
| 정보 은닉 | 외부에 노출할 부분과 숨길 부분을 명확히 구분 가능 |
| 컴파일 독립성 | 명세(Spec)만 변경되지 않으면 Body 수정은 다른 코드에 영향 없음 |
⸻
사용 방법
(1) 패키지 사양(Specification)
CREATE OR REPLACE PACKAGE math_pkg IS FUNCTION add(x NUMBER, y NUMBER) RETURN NUMBER; FUNCTION subtract(x NUMBER, y NUMBER) RETURN NUMBER; END math_pkg;
(2) 패키지 본문(Body)
CREATE OR REPLACE PACKAGE BODY math_pkg IS
FUNCTION add(x NUMBER, y NUMBER) RETURN NUMBER IS
BEGIN
RETURN x + y;
END;
FUNCTION subtract(x NUMBER, y NUMBER) RETURN NUMBER IS
BEGIN
RETURN x - y;
END;
END math_pkg;
⸻
자주 사용되는 예시
-- 함수 호출
SELECT math_pkg.add(10, 5) FROM dual;
-- 익명 블록에서 사용
BEGIN DBMS_OUTPUT.PUT_LINE(math_pkg.subtract(20, 7)); END; /
⸻
주의사항
- 사양 변경 시 전체 패키지 재컴파일 필요
- 패키지 바디 없이도 사양만으로 컴파일 가능 (예: 상수 정의용)
- 너무 많은 기능을 넣으면 복잡도 증가 → 기능별로 나누는 것이 좋음
⸻
- DBMS_OUTPUT
- DBMS_SQL
- UTL_FILE
- DBMS_SCHEDULER 등
고급 기능
(1) Oracle 19c 기본 제공 패키지 정리
Oracle은 다양한 내장 패키지를 기본으로 제공하여 파일 처리, 출력, 이메일 발송, 스케줄링, 네트워크 통신 등 다양한 작업을 수행할 수 있도록 지원합니다.
아래는 자주 사용하는 기본 제공 패키지 목록과 설명입니다.
| 패키지 이름 | 설명 |
|---|---|
| DBMS_OUTPUT | PUT_LINE을 통해 PL/SQL에서 텍스트 출력 가능. 디버깅용으로 자주 사용.
|
| UTL_FILE | 서버 디스크의 파일 읽기/쓰기 가능. 로그 저장 등에 활용됨. |
| DBMS_SQL | 동적 SQL 실행에 사용. 컴파일 시점에 SQL 문이 정해지지 않을 때 유용. |
| DBMS_SCHEDULER | 작업(Job), 프로그램(Program), 스케줄(Schedule) 등을 생성해 정기적인 작업 수행 가능. |
| DBMS_JOB | Oracle의 구버전 스케줄러. 현재는 DBMS_SCHEDULER 권장. |
| UTL_MAIL | 이메일 전송 가능. SMTP 서버 설정이 필요. |
| UTL_HTTP | HTTP 프로토콜을 이용한 외부 웹 요청 가능. REST API 호출 등에 사용. |
| DBMS_METADATA | 테이블, 뷰, 인덱스 등의 DDL 스크립트를 추출할 수 있음. |
| DBMS_STATS | 통계 정보를 수집하여 옵티마이저 성능을 최적화. |
| DBMS_ALERT / DBMS_PIPE | 세션 간 통신 기능 제공. 이벤트 기반 처리 가능. |
| DBMS_CRYPTO | 암호화, 해시, 서명 기능 제공. 보안 관련 기능 수행 가능. |
기본 제공 패키지를 사용하려면 DBA 권한 또는 특정 권한이 필요할 수 있으며, 일부 패키지는 오라클 서버 설정에 따라 기본적으로 비활성화되어 있을 수 있습니다.
⸻
(2) 사용자 정의 패키지 성능 최적화 방법
패키지를 효율적으로 사용하려면 다음의 최적화 전략을 따르는 것이 좋습니다.
1. 자주 쓰는 로직은 패키지화
- 반복적으로 사용하는 로직(예: 날짜 계산, 코드 변환 등)은 패키지에 넣어 재사용.
2. 필요한 항목만 Specification에 공개
- 외부에 보여줄 함수/프로시저만 명세에 넣고, 내부 로직은 Body에 숨기기.
- 예: 유틸 함수는 내부 전용으로 숨김 처리.
3. 전역 변수 사용 시 주의
- 패키지 전역 변수는 세션 단위로 관리되며, 모든 호출에 공유되지 않음.
- 상태 관리가 필요한 경우 전역 변수 사용보다 테이블 저장 권장.
4. 컴파일 효율성 고려
- 패키지 사양(Spec)을 변경하면 전체 Body와 관련 의존 객체가 무효화되므로 변경 최소화.
5. 바디 없는 패키지 사용
- 상수나 공용 상수 목록만 필요할 경우 Body 없이 Spec만 작성해 사용 가능.
CREATE OR REPLACE PACKAGE const_pkg IS c_tax_rate CONSTANT NUMBER := 0.1; END const_pkg;
6. 예외 처리 일관화
- 공용 예외 처리 프로시저를 패키지에 넣어, 다른 PL/SQL 코드에서 통일되게 사용 가능.
7. BULK COLLECT, FORALL 등 고급 기법 사용
- 대량 데이터를 다룰 때는 성능을 위해 BULK COLLECT와 FORALL 사용.
FORALL i IN 1..v_data.COUNT INSERT INTO my_table VALUES v_data(i);
추가 팁: 패키지 성능 모니터링
- Oracle의 DBA_OBJECTS, DBA_DEPENDENCIES 뷰 등을 통해 패키지 상태 및 의존성을 점검할 수 있습니다.
- DBMS_PROFILER 또는 DBMS_HPROF를 사용하면 PL/SQL 성능 분석도 가능합니다.
23일차 - PL/SQL 트리거]
트리거
- Oracle 트리거(Trigger)는 특정 이벤트가 발생했을 때 자동으로 실행되는 PL/SQL 블록입니다.
- 예를 들어, INSERT/UPDATE/DELETE가 발생할 때 자동으로 특정 로직을 실행할 수 있도록 설정합니다.
트리거 기본 개념
| 항목 | 설명 |
|---|---|
| 정의 | 특정 이벤트에 자동으로 반응하는 데이터베이스 객체 |
| 작동 시점 | BEFORE / AFTER / INSTEAD OF |
| 대상 이벤트 | INSERT, UPDATE, DELETE |
| 적용 대상 | 행(Row-Level) / 문장(Statement-Level) |
기본 문법
CREATE [OR REPLACE] TRIGGER 트리거명
{BEFORE | AFTER | INSTEAD OF} {INSERT | UPDATE | DELETE}
ON 테이블명
[FOR EACH ROW] -- 행 단위 트리거일 경우
[WHEN 조건] -- (선택적 조건)
BEGIN
-- 실행할 PL/SQL 블록
END;
/
예제 1
- INSERT 발생 시 로그 기록 트리거
CREATE OR REPLACE TRIGGER trg_customer_insert_log AFTER INSERT ON CUSTOMER FOR EACH ROW BEGIN INSERT INTO CUSTOMER_LOG (CUST_ID, ACTION_DATE, ACTION) VALUES (:NEW.ID, SYSDATE, 'INSERT'); END; /
- CUSTOMER 테이블에 데이터가 추가될 때, CUSTOMER_LOG 테이블에 로그를 남깁니다.
예제 2
- 급여 변경 감지 트리거 (UPDATE)
CREATE OR REPLACE TRIGGER trg_salary_change BEFORE UPDATE OF SALARY ON EMPLOYEE FOR EACH ROW WHEN (OLD.SALARY != NEW.SALARY) BEGIN INSERT INTO SALARY_AUDIT (EMP_ID, OLD_SALARY, NEW_SALARY, CHANGE_DATE) VALUES (:OLD.EMP_ID, :OLD.SALARY, :NEW.SALARY, SYSDATE); END; /
- 급여가 변경되면 SALARY_AUDIT 테이블에 변경 전/후 정보를 기록합니다.
예제 3
- DELETE 시 데이터 백업 트리거
CREATE OR REPLACE TRIGGER trg_emp_delete_backup BEFORE DELETE ON EMPLOYEE FOR EACH ROW BEGIN INSERT INTO EMPLOYEE_ARCHIVE (EMP_ID, NAME, DEPT_ID, SALARY, DELETED_AT) VALUES (:OLD.EMP_ID, :OLD.NAME, :OLD.DEPT_ID, :OLD.SALARY, SYSDATE); END; /
- 삭제 전 데이터를 백업 테이블로 복사합니다.
- 실무에서 데이터 삭제 로그를 남기기 위해 자주 사용합니다.
트리거 종류 요약
| 종류 | 설명 | 사용 예 |
|---|---|---|
| BEFORE INSERT/UPDATE/DELETE | 이벤트 발생 전에 실행 | BEFORE UPDATE ON EMPLOYEE |
| AFTER INSERT/UPDATE/DELETE | 이벤트 발생 후에 실행 | AFTER INSERT ON CUSTOMER |
| INSTEAD OF | 뷰(View)에 직접 수정이 불가할 때 대체 실행 | INSTEAD OF INSERT ON vw_customer |
| STATEMENT 트리거 | 전체 문장 1회 실행 (행마다 아님) | CREATE TRIGGER trg_all AFTER INSERT ON table |
| ROW 트리거 | 각 행마다 실행됨 | FOR EACH ROW 사용 |
시스템 트리거 (고급)
Oracle은 테이블 외에도 시스템 이벤트 트리거를 지원합니다:
CREATE OR REPLACE TRIGGER trg_logon_example AFTER LOGON ON DATABASE BEGIN INSERT INTO LOGIN_AUDIT(USER_NAME, LOGIN_TIME) VALUES (USER, SYSDATE); END; /
- 사용자가 데이터베이스에 접속할 때마다 로그인 기록을 남깁니다.
트리거 유의사항
| 주의사항 | 설 명 |
|---|---|
| 트리거는 자동 실행되므로, 무한 루프 주의 | 예: 트리거에서 다시 트리거를 부르는 경우 |
| 트리거는 성능에 영향을 줄 수 있음 | 많은 데이터에 작동하면 병목 발생 가능 |
| 트리거는 디버깅이 어렵기 때문에 주석, 로그 중요 | 로그 테이블 또는 DBMS_OUTPUT 활용 권장 |